Chapter 10: User Interfaces and Visualization - by Marti Hearst

Contents
|
Modern Information Retrieval Chapter 10: User Interfaces and Visualization - by Marti Hearst |
Contents |
To formulate a query, a user must select collections, metadata descriptions, or information sets against which the query is to be matched, and must specify words, phrases, descriptors, or other kinds of information that can be compared to or matched against the information in the collections. As a result, the system creates a set of documents, metadata, or other information type that match the query specification in some sense and displays the results to the user in some form.
Shneiderman [shneiderman97] identifies five primary
human-computer interaction styles. These are: command language,
form fillin, menu selection, direct manipulation,
and natural language.![[*]](foot_motif.gif) Each technique has been used in query
specification interfaces and each has advantages and disadvantages.
These are described below in the context of Boolean query
specification.
Each technique has been used in query
specification interfaces and each has advantages and disadvantages.
These are described below in the context of Boolean query
specification.
In modern information access systems the matching process usually employs a statistical ranking algorithm. However, until recently most commercial full-text systems and most bibliographic systems supported only Boolean queries. Thus the focus of many information access studies has been on the problems users have in specifying Boolean queries. Unfortunately, studies have shown time and again that most users have great difficulty specifying queries in Boolean format and often misjudge what the results will be [boyle84][greene90][michard82][young93].
Boolean queries are problematic for several reasons. Foremost among these is that most people find the basic syntax counter-intuitive. Many English-speaking users assume everyday semantics are associated with Boolean operators when expressed using the English words AND and OR, rather than their logical equivalents. To inexperienced users, using AND implies the widening of the scope of the query, because more kinds of information are being requested. For instance, `dogs and cats' may imply a request for documents about dogs and documents about cats, rather than documents about both topics at once. `Tea or coffee' can imply a mutually exclusive choice in everyday language. This kind of conceptual problem is well documented [boyle84][greene90][michard82][young93]. In addition, most query languages that incorporate Boolean operators also require the user to specify complex syntax for other kinds of connectors and for descriptive metadata. Most users are not familiar with the use of parentheses for nested evaluation, nor with the notions associated with operator precedence.
By serving a massive audience possessing little query-specification experience, the designers of World Wide Web search engines have had to come up with more intuitive approaches to query specification. Rather than forcing users to specify complex combinations of ANDs and ORs, they allow users to choose from a selection of common simple ways of combining query terms, including `all the words' (place all terms in a conjunction) and `any of the words' (place all terms in a disjunction).
Another Web-based solution is to allow syntactically-based query specification, but to provide a simpler or more intuitive syntax. The `+' prefix operator gained widespread use with the advent of its use as a mandatory specifier in the Altavista Web search engine. Unfortunately, users can be misled to think it is an infix AND rather than a prefix mandatory operator, and thus assume that `cat + dog' will only retrieve articles containing both terms (where in fact this query requires dog but allows cat to be optional).
Another problem with pure Boolean systems is they do not rank the retrieved documents according to their degree of match to the query. In the pure Boolean framework a document either satisfies the query or it does not. Commercial systems usually resort to ordering documents according to some kind of descriptive metadata, usually in reverse chronological order. (Since these systems usually index timely data corresponding to newspaper and news wires, date of publication is often one of the most salient features of the document.) Web-based systems usually rank order the results of Boolean queries using statistical algorithms and Web-specific heuristics.
Aside from conceptual misunderstandings of the logical meaning of AND and OR, another part of the problem with pure Boolean query specification in online bibliographic systems is the arbitrariness of the syntax and the contextlessness nature of the TTY-based interface in which they are predominantly available. Typically input is typed at a prompt and is of a form something like the following:
COMMAND ATTRIBUTE value {BOOLEAN-OPERATOR ATTRIBUTE value}*
e.g.,
FIND PA darwin AND TW species OR TW descent
or
FIND TW Mt St. Helens AND DATE 1981
(These examples are derived from the syntax of the telnet interface to the University of California Melvyl system [lync92].) The user must remember the commands and attribute names, which are easily forgotten between usages of the system [meadow89]. Compounding this problem, despite the fact that the command languages for the two main online bibliographic systems at UC Berkeley have different but very similar syntaxes, after more than ten years one of the systems still reports an error if the author field is specified as PA instead of PN, as is done in the other system. This lack of flexibility in the syntax is characteristic of interfaces designed to suit the system rather than its users.
The new Web-based version of Melvyl
provides form fillin and menu selection so the user no longer has to
remember the names and types of attributes available. Users select
metadata types from listboxes and attributes are shown explicitly,
allowing selection as an alternative to specification. For example, the
`search type' field is adjacent to an entry form in which users can enter
keywords, and a choice between AND and NOT is provided adjacent to a list
of the available document types (editorial, feature, etc.). Only the
metadata associated with a given collection is shown in the context of
search over that collection. (Unfortunately the system is restricted to
searching over only one database at a time. It does however provide a
mechanism for applying a previously executed search to a new
database.) See Figure ![[*]](cross_ref_motif.gif) .
.
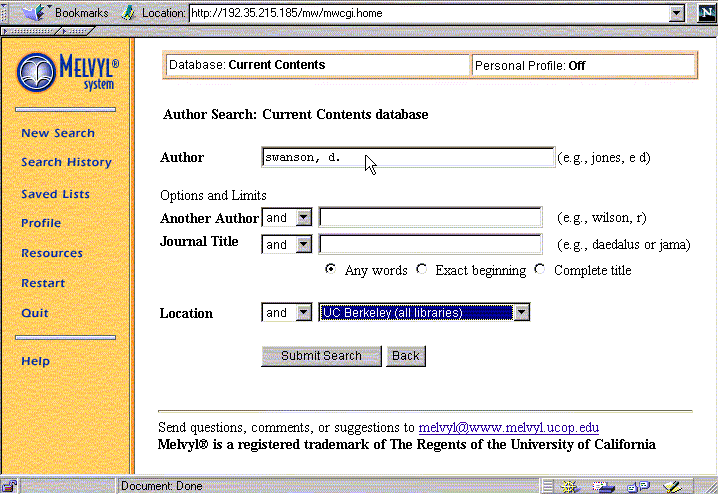
The Web-based version of Melvyl also allows retention of context between searches, storing prior results in tables and hyperlinking these results to lists containing the retrieved bibliographic information. Users can also modify any of the previously submitted queries by selecting a checkbox beside the record of the query. The graphical display makes explicit and immediate many of the powerful options of the system that most users would not learn using the command-line version of the interface.
Bit-mapped displays are an improvement over command-line interface, but
do not solve all the problems. For example, a blank entry form is in
some ways not much better than a TTY prompt, because it does not
provide the user with clues about what kinds of terms should be
entered.
Yet another problem with Boolean queries is that their strict interpretation tends to yield result sets that are either too large, because the user includes many terms in a disjunct, or are empty, because the user conjoins terms in an effort to reduce the result set. This problem occurs in large part because the user does not know the contents of the collection or the role of terms within the collection.
A common strategy for dealing with this problem, employed in systems with command-line-based interfaces like DIALOG's, is to create a series of short queries, view the number of documents returned for each, and combine those queries that produce a reasonable number of results. For example, in DIALOG, each query produces a resulting set of documents that is assigned an identifying name. Rather than returning a list of titles themselves, DIALOG shows the set number with a listing of the number of matched documents. Titles can be shown by specifying the set number and issuing a command to show the titles. Document sets that are not empty can be referred to by a set name and combined with AND operations to produce new sets. If this set in turn is too small, the user can back up and try a different combination of sets, and this process is repeated in pursuit of producing a reasonably sized document set.
This kind of query formulation is often called a faceted query, to indicate that the user's query is divided into topics or facets, each of which should be present in the retrieved documents [meadow89][harter86]. For example, a query on drugs for the prevention of osteoporosis might consist of three facets, indicated by the disjuncts
(osteoporosis OR `bone loss')(drugs OR pharmaceuticals)
(prevention OR cure)
This query implies that the user would like to view documents that contain all three topics.
A technique to impose an ordering on the results of Boolean queries is what is known as post-coordinate or quorum-level ranking (Chapter 8) [salton89]. In this approach, documents are ranked according to the size of the subset of the query terms they contain. So given a query consisting of `cats,' `dogs,' `fish,' and `mice,' the system would rank a document with at least one instance of `cats,' `dogs,' and `fish' higher than a document containing 30 occurrences of `cats' but no occurrences of the other terms.
Combining faceted queries with quorum ranking yields a situation intermediate
between full Boolean syntax and free-form natural
language queries. An interface for specifying this kind of
interaction can consist of a list of entry lines. The user enters one
topic per entry line, where each topic consists of a list of
semantically related terms that are combined in a disjunct. Documents
that contain at least one term from each facet are ranked higher than
documents containing terms only from one or a few facets. This helps
ensure that documents which contain discussions of several of the
user's topics are ranked higher than those that contain only one
topic. By only requiring that one term from each facet be matched,
the user can specify the same concept in several different ways in the
hopes of increasing the likelihood of a match. If combined with
graphical feedback about which subsets of terms matched the document,
the user can see the results of a quorum ranking by topic rather than
by word. Section describes the TileBars
interface which provides this type of feedback.
This idea can be extended yet another step by allowing users to weight
each facet. More likely to be readily usable, however, is a default
weighting in which the facet listed highest is assigned the most
weight, the second facet is assigned less weight, and so on, according to
some distribution over weights.
Direct manipulation interfaces provide an alternative to command-line syntax. The properties of direct manipulation are (p. 205) [shneiderman97]: (1) continuous representation of the object of interest, (2) physical actions or button presses instead of complex syntax, and (3) rapid incremental reversible operations whose impact on the object of interest is immediately visible. Direct manipulation interfaces often evoke enthusiasm from users, and for this reason alone it is worth exploring their use. Although they are not without drawbacks, they are easier to use than other methods for many users in many contexts.
Several variations of graphical interfaces, both directly manipulable
and static, have been developed for simplifying the specification of
Boolean syntax. User studies tend to reveal that these graphical
interfaces are more effective in terms of accuracy and speed than
command-language counterparts. Three such approaches are described
below.
Graphical depictions of Venn diagrams have been proposed several
times as a way to improve Boolean query specification. A query term
is associated with a ring or circle and intersection of rings
indicates conjunction of terms. Typically the number of documents
that satisfy the various conjuncts are displayed within the
appropriate segments of the diagram. Several studies have found such
interfaces more effective than their command-language-based syntax
[jones98][hertzum96][michard82]. Hertzum and Frokjaer found that a
simple Venn diagram representation produced faster and more accurate
results than a Boolean query syntax. However, a problem with this
format is the limitations on the complexity of the expression. For
example, a maximum of three query terms can be ANDed together in a
standard Venn diagram. Innovations have been designed to get around
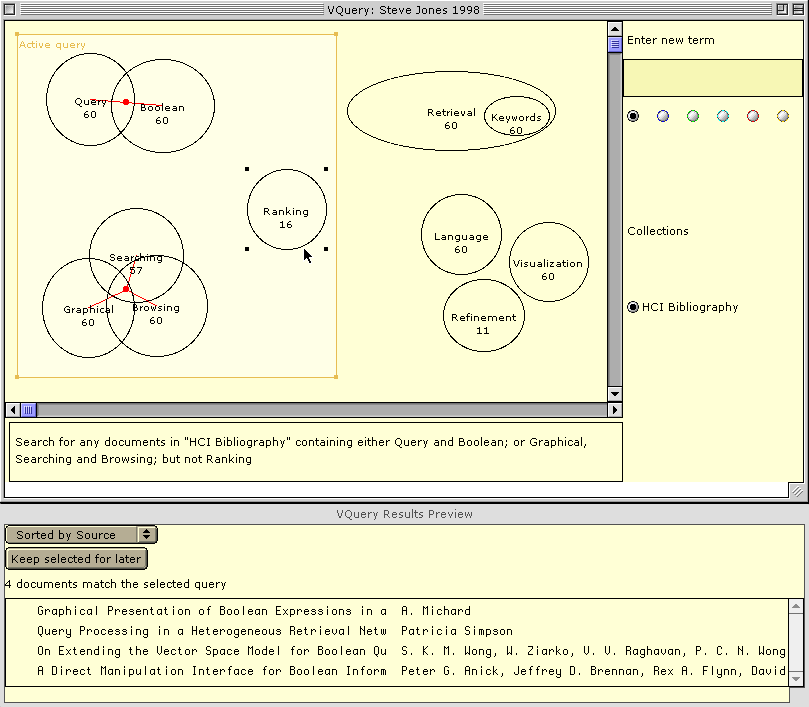
this problem, as seen in the VQuery system [jones98] (see Figure
). In VQuery, a direct manipulation interface allows
users to assign any number of query terms to ovals. If two or more
ovals are placed such that they overlap with one another, and if the
user selects the area of their intersection, an AND is implied among
those terms. (In Figure , the term `Query' is
conjoined with `Boolean'.) If the user selects outside the area of
intersection but within the ovals, an OR is implied among the
corresponding terms. A NOT operation is associated with any term
whose oval appears in the active area of the display but which
remains unselected (in the figure, NOT `Ranking' has been
specified). An active area indicates the current query; all groups of
ovals within the active area are considered part of a conjunction. Ovals
containing query terms can be moved out of the active area for later
use.
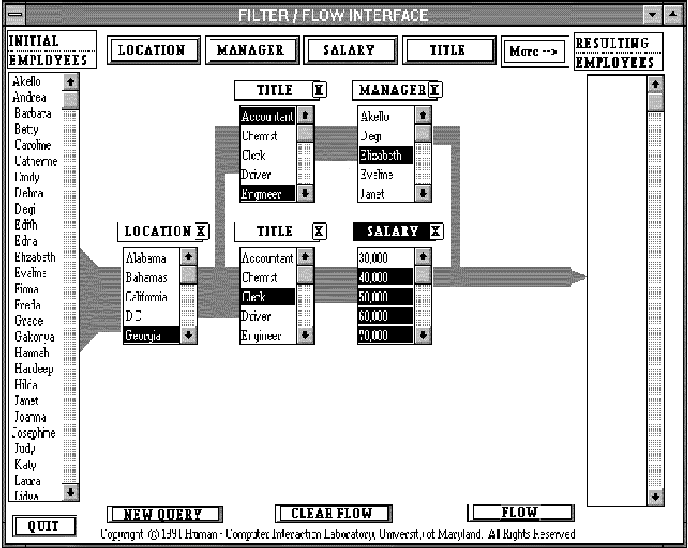
Young and Shneiderman [young93] found improvements over standard
Boolean syntax by providing users with a direct manipulation filter-flow model. The user is shown a scrollable list of attribute
types on the left-hand side and selects attributes from another list of
attribute types shown across the top of the screen. Clicking on an
attribute name causes a listbox containing values for those attributes
to be displayed in the main portion of the screen. The user then
selects which values of the attributes to let the flow go through.
Placing two or more of these attributes in sequence creates the
semantics of a conjunct over the selected values. Placing two or more
of these in parallel creates the semantics of a disjunct. The number
of documents that match the query at each point is indicated by the
width of the `water' flowing from one attribute to the next. (See
Figure .) A conjunct can reduce the amount of
flow. The items that match the full query are shown on the far
right-hand side. A user study found that fewer errors were made using
the filter flow model than a standard SQL database query. However,
the examples and study pertain only to database querying rather than
information access, since the possible query terms for information
access cannot be represented realistically in a scrollable list. This
interface could perhaps be modified to better suit information access
applications by having the user supply initial query terms, and using the
attribute selection facility to show those terms that are conceptually
related to the query terms. Another alternative is to use this display as
a category metadata selection interface (see Section
).
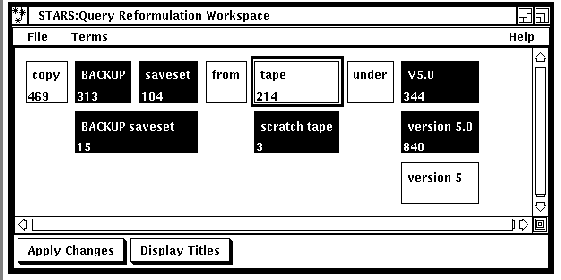
Anick et al. [anick90b] describe another innovative direct
manipulation interface for Boolean queries. Initially
the user types a natural language query which is
automatically converted to a representation in which each query term
is represented within a block. The blocks are arranged into rows and
columns (See Figure ). If two or more blocks appear
along the same row they are considered to be ANDed together. Two or
more blocks within the same column are ORed. Thus the user can
represent a technical term in multiple ways within the same query,
providing a kind of faceted query interface.
For example, the terms `version 5', `version 5.0', and `v5'
might be shown in the same column. Users can quickly experiment with
different combinations of terms within Boolean queries simply by
activating and deactivating blocks. This facility also allows users to
have multiple representations of the same term in different places
throughout the display, thus allowing rapid feedback on the consequences
of specifying various combinations of query terms. Informal evaluation
of the system found that users were able to learn to manipulate the
interface quickly and enjoyed using it. It was not formally compared to
other interaction techniques
[anick90b].
This interface provides a kind of query preview: a low cost, rapid turnaround visualization of the results of many variations on a query [plaisant97]. Another example of query previewing can be found in some help systems, which show all the words in the index whose first letters match the characters that the user has typed so far. The more characters typed, the fewer possible matches become available. The HiBrowse system described above [pollitt97] also provides a kind of preview for viewing category hierarchies and facets, showing how many documents would be matched if a category one level below the current one were selected. It perhaps could be improved by showing the consequences of more combinations of categories in an animated manner. If based on prior action and interests of the user, query previewing may become more generally applicable for information access interfaces.
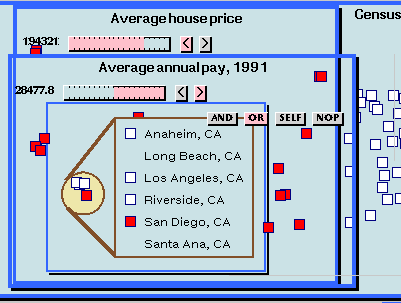
A final example of a graphical approach to query specification is the
use of magic lenses. Fishkin and Stone have suggested an extension to
the usage of this visualization tool for the specification of Boolean
queries [fishkin95]. Information is represented as lists or
icons within a 2D space. Lenses act as filters on the document
set. (See Figure .) For example, a word can be
associated with a transparent lens. When this lens is placed over an
iconic representation of a set of documents, it can cause all
documents that do not contain a given word to disappear. If a second
lens representing another word is then laid over the first, the lenses
combine to act as a conjunction of the two words with the document
set, hiding any documents that do not contain both words. Additional
information can be adjusted dynamically, such as a minimum threshold
for how often the term occurs in the documents, or an on-off switch
for word stemming. For example, Figure shows a disjunctive query that finds cities with relatively
low housing prices or high annual salaries. One lens `calls out' a clump of southern California cities, labeling each.
Above that is a lens screening for cities with average house price
below $194,321 (the data is from 1990), and above this one is a lens
screening for cities with average annual pay above $28,477. This approach, while promising, has not been
evaluated in an information access setting.
In general, proximity information can be quite effective at improving precision of searches. On the Web, the difference between a single-word query and a two-word exact phrase match can mean the difference between an unmanageable mess of retrieved documents and a short list with mainly relevant documents.
A large number of methods for specifying phrases have been developed. The syntax in LEXIS-NEXISrequires the proximity range to be specified with an infix operator. For example, `white w/3 house' means `white within 3 words of house, independent of order.' Exact proximity of phrases is specified by simply listing one word beside the other, separated by a space. A popular method used by Web search engines is the enclosure of the terms between quotation marks. Shneiderman et al. [shneiderman98] suggest providing a list of entry labels, as suggested above for specifying facets. The difference is, instead of a disjunction, the terms on each line are treated as a phrase. This is suggested as a way to guide users to more precise query specification.
The disadvantage of these methods is that they require exact match of phrases, when it is often the case (in English) that one or a few words comes between the terms of interest. For example, in most cases the user probably wants `president' and `lincoln' to be adjacent, but still wants to catch cases of the sort `President Abraham Lincoln.' Another consideration is whether or not stemming is performed on the terms included in the phrase. The best solution may be to allow users to specify exact phrases but treat them as small proximity ranges, with perhaps an exponential fall-off in weight in terms of distance of the terms. This has been shown to be a successful strategy in non-interactive ranking algorithms [clarke96]. It has also been shown that a combination of quorum ranking of faceted queries with the restriction that the facets occur within a small proximity range can dramatically improve precision of results [hearst96a][mitra98].
Statistical ranking algorithms have the advantage of allowing users to specify queries naturally, without having to think about Boolean or other operators. But they have the drawback of giving the user less feedback about and control over the results. Usually the result of a statistical ranking is the listing of documents and the association of a score, probability, or percentage beside the title. Users are given little feedback about why the document received the ranking it did and what the roles of the query terms are. This can be especially problematic if the user is particularly interested in one of the query terms being present.
One search strategy that can help with this particular problem with statistical ranking algorithms is the specification of `mandatory' terms within the natural language query. This in effect helps the user control which terms are considered important, rather than relying on the ranking algorithm to correctly weight the query terms. But knowing to include a mandatory specification requires the user to know about a particular command and how it works.
The preceding discussion assumes that a natural language query entered by the user is treated as a bag of words, with stopwords removed, for the purposes of document match. However, some systems attempt to parse natural language queries in order to extract concepts to match against concepts in the text collection [jacobs93b][mccune85][strzalkowski99].
Alternatively, the natural language syntax of a question can be used to attempt to answer the question. (Question answering in information access is different than that of database management systems, since the information desired is encoded within the text of documents rather than specified by the database schema.) The Murax system [kupiec93] determines from the syntax of a question if the user is asking for a person, place, or date. It then attempts to find sentences within encyclopedia articles that contain noun phrases that appear in the question, since these sentences are likely to contain the answer to the question. For example, given the question `Who was the Pulitzer Prize-winning novelist that ran for mayor of New York City?,' the system extracts the noun phrases `Pulitzer Prize,' `winning novelist,' `mayor,' and `New York City.' It then looks for proper nouns representing people's names (since this is a `who' question) and finds, among others, the following sentences:
The Armies of the Night (1968), a personal narrative of the 1967 peace march on the Pentagon, won Mailer the Pulitzer Prize and the National Book Award.
In 1969 Mailer ran unsuccessfully as an independent candidate for mayor of New York City.
Thus the two sentences link together the relevant noun phrases and the system hypothesizes (correctly) from the title of the article in which the sentences appear that Norman Mailer is the answer.
Another approach to automated question answering is the FAQ finder system which matches question-style queries against question-answer pairs on various topics [burke97]. The system uses a standard IR search to find the most likely FAQ (frequently asked questions) files for the question and then matches the terms in the question against the question portion of the question-answer pairs.
A less automated approach to question answering can be found in the Ask Jeeves system [askjeeves]. This system makes use of hand-picked Web sites and matches these to a predefined set of question types. A user's query is first matched against the question types. The user selects the most accurate rephrase of their question and this in turn is linked to suggested Web sites. For example, the question `Who is the leader of Sudan?' is mapped into the question type `Who is the head of state of X (Sudan)?' where the variable is replacedby a listbox of choices, with Sudan the selected choice in this case. This is linked to a Web page that lists current heads of state. The system also automatically substitutes in the name `Sudan' in a query against that Web page, thus bringing the answer directly to the user's attention. The question is also sent to standard Web search engines. However, a system is only as good as its question templates. For example a question `Where can I find reviews of spas in Calistoga?' matches the question `Where can I find X (reviews) of activities for children aged Y (1)?' and `Where can I find a concise encyclopedia article on X (hot springs)?'