Chapter 10: User Interfaces and Visualization - by Marti Hearst

Contents
|
Modern Information Retrieval Chapter 10: User Interfaces and Visualization - by Marti Hearst |
Contents |
This section discusses interface techniques for placing the current document set in the context of other information types, in order to make the document set more understandable. This includes showing the relationship of the document set to query terms, collection overviews, descriptive metadata, hyperlink structure, document structure, and to other documents within the set.
The most common way to show results for a query is to list information
about documents in order of their computed relevance to the query.
Alternatively, for pure Boolean ranking, documents are listed
according to a metadata attribute, such as date. Typically the
document list consists of the document's title and a subset of
important metadata, such as date, source, and length of the article.
In systems with statistical ranking, a numerical score or percentage
is also often shown alongside the title, where the score indicates a
computed degree of match or probability of relevance. This kind of
information is sometimes referred to as a document surrogate.
See Figure ![[*]](cross_ref_motif.gif) from [witten98].
from [witten98].
Some systems provide users with a choice between a short and a detailed view. The detailed view typically contains a summary or abstract. In bibliographic systems, the author-written or service-written abstract is shown. Web search engines automatically generate excerpts, usually extracting the first few lines of non-markup text in the Web page.
In most interfaces, clicking on the document's title or an iconic representation of the document shown beside the title will bring up a view of the document itself, either in another window on the screen, or replacing the listing of search results. (In traditional bibliographic systems, the full text was unavailable online, and only bibliographic records could be readily viewed.)
In systems in which the user can view the full text of a retrieved document, it is often useful to highlight the occurrences of the terms or descriptors that match those of the user's query. It can also be useful for the system to scroll the view of the document to the first passage that contains one or more of the query terms, and highlight the matched terms in a contrasting color or reverse video. This display is thought to help draw the user's attention to the parts of the document most likely to be relevant to the query. Highlighting of query terms has been found time and again to be a useful feature for information access interfaces [landauer93],[march] (p.31). Color highlighting has also recently been found to be useful for scanning lists of bibliographic records [baldonado98].
A facility related to highlighting is the keyword-in-context (KWIC) document surrogate. Sentence fragments, full sentences, or groups of sentences that contain query terms are extracted from the full text and presented for viewing along with other kinds of surrogate information (such as document title and abstract). Note that a KWIC listing is different than an abstract. An abstract summarizes the main topics of the document but might not contain references to the terms within the query. A KWIC extract shows sentences that summarize the ways the query terms are used within the document. This display can show not only which subsets of query terms occur in the retrieved documents, but also the context they appear in with respect to one another.
Tradeoff decisions must be made between how many lines of text to show and which lines to display. It is not known which contexts are best selected for viewing but results from text summarization research suggest that the best fragments to show are those that appear near the beginning of the document and that contain the largest subset of query terms [kupiec95]. If users have specified which terms are more important than others, then those fragments containing important terms should be shown before those that contain only less important terms. However, to help retain coherence of the excerpts, selected sentences should be shown in order of their occurrence in the original document, independent of how many search terms they contain.
The KWIC facility is usually not shown in Web search result display, most likely because the system must have a copy of the original document available from which to extract the sentences containing the search terms. Web search engines typically only retain the index without term position information. Systems that index individual Web sites can show KWIC information in the document list display.
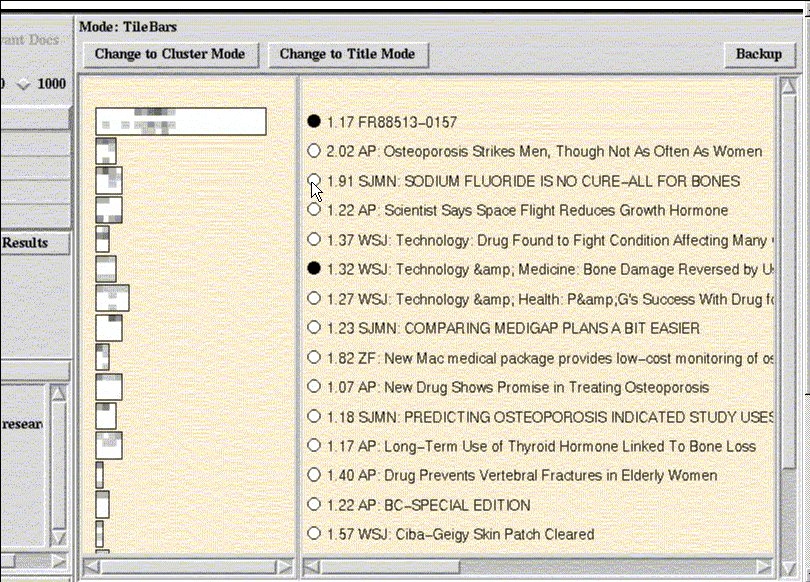
A more compact form of query term hit display is made available through the TileBars interface. The user enters a query in a faceted format, with one topic per line. After the system retrieves documents (using a quorum or statistical ranking algorithm), a graphical bar is displayed next to the title of each document showing the degree of match for each facet. TileBars thus illustrate at a glance which passages in each article contain which topics - and moreover, how frequently each topic is mentioned (darker squares represent more frequent matches).
Each document is represented by a rectangular bar. Figure
shows an example. The bar is subdivided into rows
that correspond to the query facets. The top row of each TileBar
corresponds to `osteoporosis,' the second row to `prevention,' and
the third row to `research.' The bar is also subdivided into
columns, where each column refers to a passage within the document.
Hits that overlap within the same passage are more likely to indicate
a relevant document than hits that are widely dispersed throughout the
document [hearst96a]. The patterns are meant to indicate whether
terms from a facet occur as a main topic throughout the document, as a
subtopic, or are just mentioned in passing.
The darkness of each square corresponds to the number of times the query occurs in that segment of text; the darker the square the greater the number of hits. White indicates no hits on the query term. Thus, the user can quickly see if some subset of the terms overlap in the same segment of the document. (The segments for this version of the interface are fixed blocks of 100 tokens each.)
The first document can be seen to have considerable overlap among the topics of interest towards the middle, but not at the beginning or the end (the actual end is cut off). Thus it most likely discusses topics in addition to research into osteoporosis. The second through fourth documents, which are considerably shorter, also have overlap among all terms of interest, and so are also probably of interest to the user. (The titles help to verify this.) The next three documents are all long, and from the TileBars we can tell they discuss research and prevention, but do not even touch on osteoporosis, and so probably are not of interest.
Because the TileBars interface allows the user to specify the query in terms of facets, where the terms for each facet are listed on anentry line, a color can be assigned to each facet. When the user displays a document with query term hits, the user can quickly ascertain what proportion of search topics appear in a passage based only on how many different highlight colors are visible. Most systems that use highlighting use only a single color to bring attention to all of the search terms.
It would be difficult for users to specify in advance which patterns of term hits they are interested in. Instead, TileBars allows users to scan graphic representations and recognize which documents are and are not of interest. It may be the case that TileBars may be most useful for helping users discard misleadingly interesting documents, but only preliminary studies have been conducted to date. Passages can correspond to paragraphs or sections, fixed sized units of arbitrary length, or to automatically determined multiparagraph segments [hearst95b].
The SeeSoft visualization [eick94] represents text in a manner
resembling columns of newspaper text, with one `line' of text on
each horizontal line of the strip. (See Figure .)
The representation is compact and aesthetically pleasing. Graphics
are used to abstract away the details, providing an overview showing
the amount and shape of the text. Color highlighting is used to pick
out various attributes, such as where a particular word appears in the
text. Details of a smaller portion of the display can be viewed via a
pop-up window; the overview shows more of the text but in less detail.

SeeSoft was originally designed for software development, in which a line of text is a meaningful unit of information. (Programmers tend to place each individual programming statement on one line of text.) Thus SeeSoft shows attributes relevant to the programming domain, such as which lines of code were modified by which programmer, and how often particular lines have been modified, and how many days have elapsed since the lines were last modified. The SeeSoft developers then experimented with applying this idea to the display of text, although this has not been integrated into an information access system. Color highlighting is used to show which characters appear where in a book of fiction, and which passages of the Bible contain references to particular people and items. Note the use of the abstraction of an entire line to stand for a single word such as a character's name (even though though this might obscure a tightly interwoven conversation between two characters).
Other visualization ideas have been developed to show a different kind
of information about the relationship between query terms and
retrieved documents. Rather than showing how query terms appear
within individual documents, as is done in KWIC interfaces and
TileBars, these systems display an overview or summary of the
retrieved documents according to which subset of query terms they
contain. The following subsections describe variations on this idea.
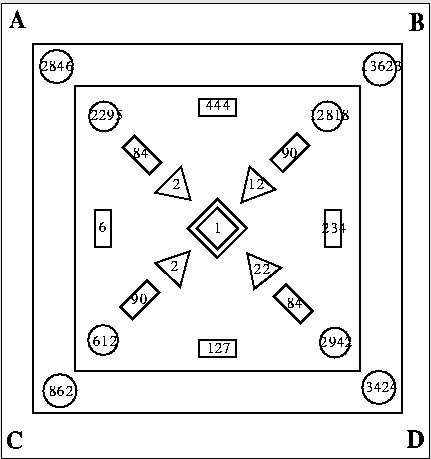
The InfoCrystal shows how many documents contain each subset of query
terms [spoerri93]. This relieves the user from the need to specify
Boolean ANDs and ORs in their query, while still showing which
combinations of terms actually appear in documents that were ordered
by a statistical ranking (although beyond four terms the interface
becomes difficult to understand). The InfoCrystal allows
visualization of all possible relations among N user-specified
`concepts' (or Boolean keywords). The InfoCrystal displays, in a
clever extension of the Venn diagram paradigm, the number of documents
retrieved that have each possible subset of the N concepts. Figure
shows a sketch of what the InfoCrystal might
display as the result of a query against four keywords or Boolean
phrases, labeled A, B, C, and D. The diamond in the center indicates
that one document was discovered that contains all four keywords. The
triangle marked with `12' indicates that 12 documents were found
containing attributes A, B, and D, and so on.
The InfoCrystal does not show proximity among the terms within the documents, nor their relative frequency. So a document that contains dozens of hits on `volcano' and `lava' and one hit on `Mars' will be grouped with documents that contain mainly hits on `Mars' but just one mention each of `volcano' and `lava.'
Graphical presentations that operate on similar principles are VIBE
[korfhage91] and Lyberworld [hemmje94]. In these displays,
query terms are placed in an abstract graphical space. After the
search, icons are created that indicate how many documents contain
each subset of query terms. The subset status of each group of
documents is indicated by the placement of the icon. For example, in
VIBE a set of documents that contain three out of five query terms are
shown on an axis connecting these three terms, at a point midway between
the representations of the three query terms in question. (See Figure
.) Lyberworld presents a 3D version of this idea.
Several researchers have employed a graphical depiction of a mathematical lattice for the purposes of query formulation, where the query consists of a set of constraints on a hierarchy of categories (actually, semantic attributes in these systems) [gpedersen93][carpineto96]. This is one solution to the problem of displaying documents in terms of multiple attributes; a document containing terms A, B, C, and D could be placed at a point in the lattice with these four categories as parents. However, if such a representation were to be applied to retrieval results instead of query formulation, the lattice layout would in most cases be too complex to allow for readability.
None of the displays discussed in this subsection have been evaluated for effectiveness at improving query specification or understanding of retrieval results, but they are intriguing ideas and perhaps are useful in conjunction with other displays.
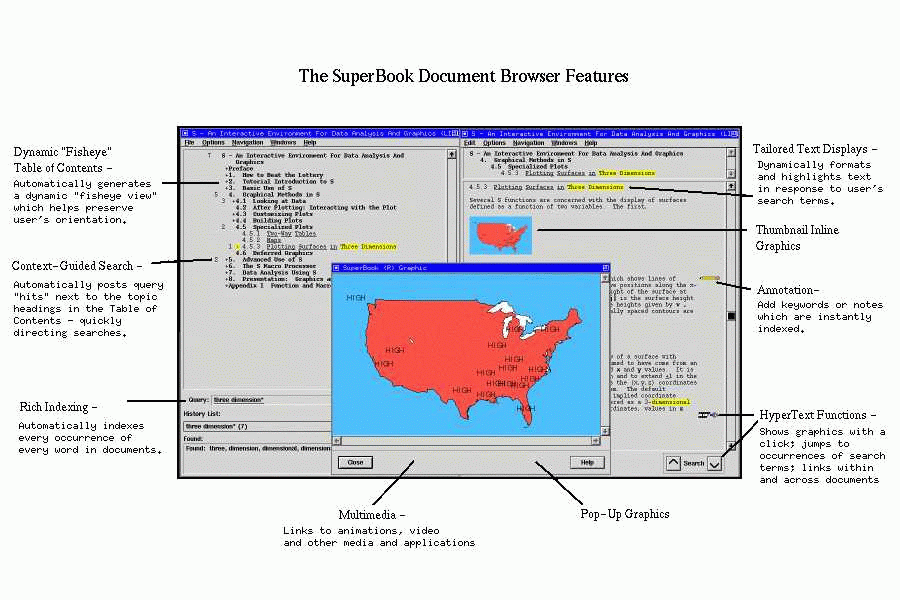
The SuperBook system [landauer93][egan89a][egan89b] makes use of the structure of a large document to display query term hits in context. The table of contents (TOC) for a book or manual are shown in a hierarchy on the left-hand side of the display, and full text of a page or section is shown on the right-hand side. The user can manipulate the table of contents to expand or contract the view of sections and subsections. A focus-plus-context mechanism is used to expand the viewing area of the sections currently being looked at and compress the remaining sections. When the user moves the cursor to another part of the TOC, the display changes dynamically, making the new focus larger and shrinking down the previously observed sections.
After the user specifies a query on the book, the search results are
shown in the context of the table of contents hierarchy. (See Figure
.) Those sections that contain search hits are
made larger and the others are compressed. The query terms that
appear in chapter or section names are highlighted in reverse video.
When the user selects a page from the table of contents view, the page
itself is displayed on the right-hand side and the query terms within
the page are highlighted in reverse video.
The SuperBook designers created innovative techniques for evaluating its special features. Subjects were compared using this system against using paper documentation and against a more standard online information access system. Subjects were also compared on different kinds of carefully selected tasks: browsing topics of interest, citation searching, searching to answer questions, and searching and browsing to write summary essays. For most of the tasks SuperBook subjects were faster and more accurate or equivalent in speed and accuracy to a standard system. When differences arose between SuperBook and the standard system, the investigators examined the logs carefully and hypothesized plausible explanations. After the initial studies, they modified SuperBook according to these hypotheses and usually saw improvements as a result [landauer93].
The user studies on the improved system showed that users were faster
and more accurate at answering questions in which some of the relevant
terms were within the section titles themselves, but they were also
faster and more accurate at answering questions in which the query
terms fell within the full text of the document only, as compared both
to a paper manual and to an interface that did not provide such
contextualizing information. SuperBook was not faster than paper when
the query terms did not appear in the document text or the table of
contents. This and other evidence from the SuperBook studies suggests
that query term highlighting is at least partially responsible for
improvements seen in the system.
In section we saw the use of category
or directory information for providing overviews of text collection
content. Category metadata can also be used to place the results of a
query in context.
For example, the original formulation of SuperBook allowed navigation within a highly structured document, a computer manual. The CORE project extended the main idea to a collection of over 1000 full-text chemistry articles. A study of this representation demonstrated its superiority to a standard search system on a variety of task types [egan91]. Since a table of contents is not available for this collection, context is provided by placing documents within a category hierarchy containing terms relevant to chemistry. Documents assigned a category are listed when that category is selected for more detailed viewing, and the categories themselves are organized into a hierarchy, thus providing a hierarchical view on the collection.
Another approach to using predefined categories to provide context for retrieval results is demonstrated by the DynaCat system [pratt97]. The DynaCat system organizes retrieved documents according to which types of categories, selected from the large MeSH taxonomy, are known in advance to be important for a given query type. DynaCat begins with a set of query types known to be useful for a given user population and collection. One query type can encompass many different queries. For example, the query type `Treatment-Adverse Effects' covers queries such as `What are the complications of a mastectomy?' as well as `What are the side-effects of aspirin?' Documents are organized according to a set of criteria associated with each query type. These criteria specify which types of categories that are acceptable to use for organizing the documents and consequently, which categories should be omitted from the display. Once categories have been assigned to the retrieved documents, a hierarchy is formed based on where the categories exist within MeSH. The algorithm selects only a subset of the category labels that might be assigned to the document to be used in the organization.
Figure shows the results for a query on
breast cancer prevention. The interface is tiled into three
windows. The top window displays the user's query and the
number of documents found. The left window shows the categories in the
first two levels of the hierarchy, providing a
table of contents view of the organization of search results. The
right pane displays all the categories in the hierarchy and the titles
of the documents that belong in those categories.
An obstacle to using category labels to organize retrieval results is the requirement of precompiled knowledge about which categories are of interest for a particular user or a particular query type. The SONIA system [sahami98] circumvents this problem by using a combination of unsupervised and supervised methods to organize a set of documents. The unsupervised method (document clustering similar to Scatter/Gather) imposes an initial organization on a user's personal information collection or on a set of documents retrieved as the result of a query. The user can then invoke a direct manipulation interface to make adjustments to this initial clustering, causing it to align more closely with their preferences (because unsupervised methods do not usually produce an organization that corresponds to a human-derived category structure [hearst98a]). The resulting organization is then used to train a supervised text categorization algorithm which automatically classifies any new documents that are added to the collection. As the collection grows it can be periodically reorganized by rerunning the clustering algorithm and redoing the manual adjustments.
Although the SuperBook authors describe it as a hypertext system, it is actually better thought of as a means of showing search results in the context of a structure that users can understand and view all at once. The hypertext component was not analyzed separately to assess its importance, but it usually is not mentioned by the authors when describing what is successful about their design. In fact, it seems to be responsible for one of the main problems seen with the revised version of the system -- that users tend to wander off (often unintentionally) from the pages they are reading, thus causing the time spent on a given topic to be longer for SuperBook in some cases. (Using completion time to evaluate users on browsing tasks can be problematic, however, since by definition browsing is a casual, unhurried process [waterworth91].)
This wandering may occur in part because SuperBook uses a non-standard kind of hypertext, in which any word is automatically linked to occurrences of the same word in other parts of the document. This has not turned out to be how hypertext links are created in practice. Today, hyperlinked help systems and hyperlinks on the Web make much more discriminating use of hyperlink connections (in part since they are usually generated by an author rather than automatically). These links tend to be labeled in a somewhat meaningful manner by their surrounding context. Back-of-the-book indexes often do not contain listings of every occurrence of a word, but rather to the more important uses or the beginnings of series of uses. Automated hypertext linking should perhaps be based on similar principles. Additionally, at least one study showed that users formed better mental models of a small hypertext system that was organized hierarchically than one that allowed more flexible access [edwards88]. Problems relating to navigation of hypertext structure have long been suspected and investigated in the hypertext literature [Con87][mcaleese88][kim95][halasz87].
More recent work has made better use of hyperlink information for providing context for retrieval results. Some of this work is described below.
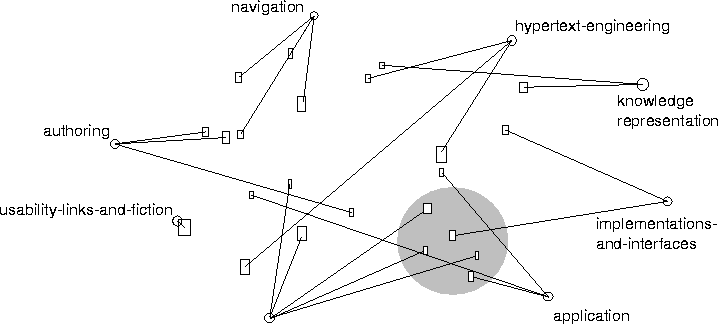
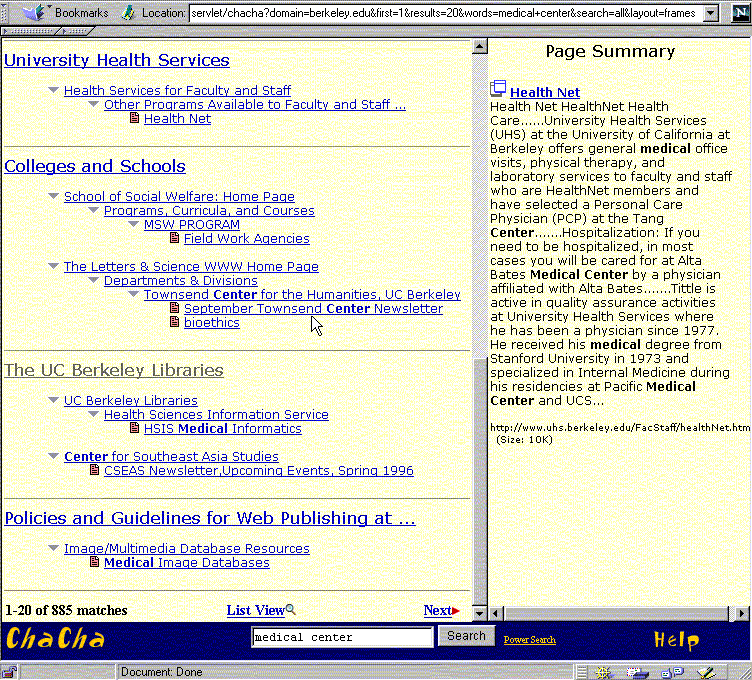
The Cha-Cha intranet search system [chen98] extends the SuperBook idea to
a large heterogeneous Web site such as might be found in an
organization's intranet. Figure shows an example.
This system differs from SuperBook in several ways. On most Web sites
there is no existing real table of contents or category structure, and
an intranet like those found at large universities or large
corporations is usually not organized by one central unit. Cha-Cha
uses link structure present within the site to create what is intended
to be a meaningful organization on top of the underlying chaos. After
the user issues a query, the shortest paths from the root page to each
of the search hits are recorded and a subset of these are selected to
be shown as a hierarchy, so that each hit is shown only once. (Users
can begin with a query, rather than with a table of contents view.)
If a user does not know to use the term `health center' but instead
queries on `medical center,' if `medical' appears as a term in a
document within the health center part of the Web, the home page (or
starting point) of this center will be presented as well as the more
specific hits. Users can then either query or navigate within a
subset of sites if they wish. The organization produced by this simple
method is surprisingly comprehensible on theUC Berkeley site. It
seems especially useful for providing the information about the
sources (the Web server) associated with the search hits, whose titles
are often cryptic.
The AMIT system [wittenburg97] also applies the basic ideas behind SuperBook to the Web, but focuses on a single-topic Web site, which is likely to have a more reasonable topic structure than a complex intranet. The link structure of the Web site is used as contextualizing information but all of the paths to a given document are shown and focus-plus-context is used to emphasize subsets of the document space. The WebTOC system [nation97] is similar to AMIT but focuses on showing the structure and number of documents within each Web subhierarchy, and is not tightly coupled with search.
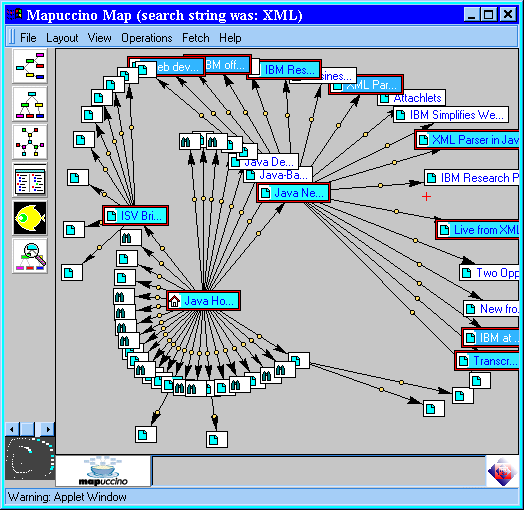
The Mapuccino system (formerly WebCutter) [WebCutter] allows the user
to issue a query
on a particular Web site. The system crawls the site in real-time,
checking each encountered page for relevance to the query. When
a relevant page is found, the weights on that page's outlinks are increased.
Thus, the search is based partly on an assumption that relevant pages
will occur near one another in the Web site. The subset of the Web
site that has been crawled is depicted graphically in a
nodes-and-links view (see Figure ).
This kind of displaydoes not provide the user with
information about what the contents of the pages are, but rather
only shows their link structure. Other researchers have also
investigated spreading activation among hypertext links as a way to
guide an information retrieval system, e.g., [frei94][menczer98].
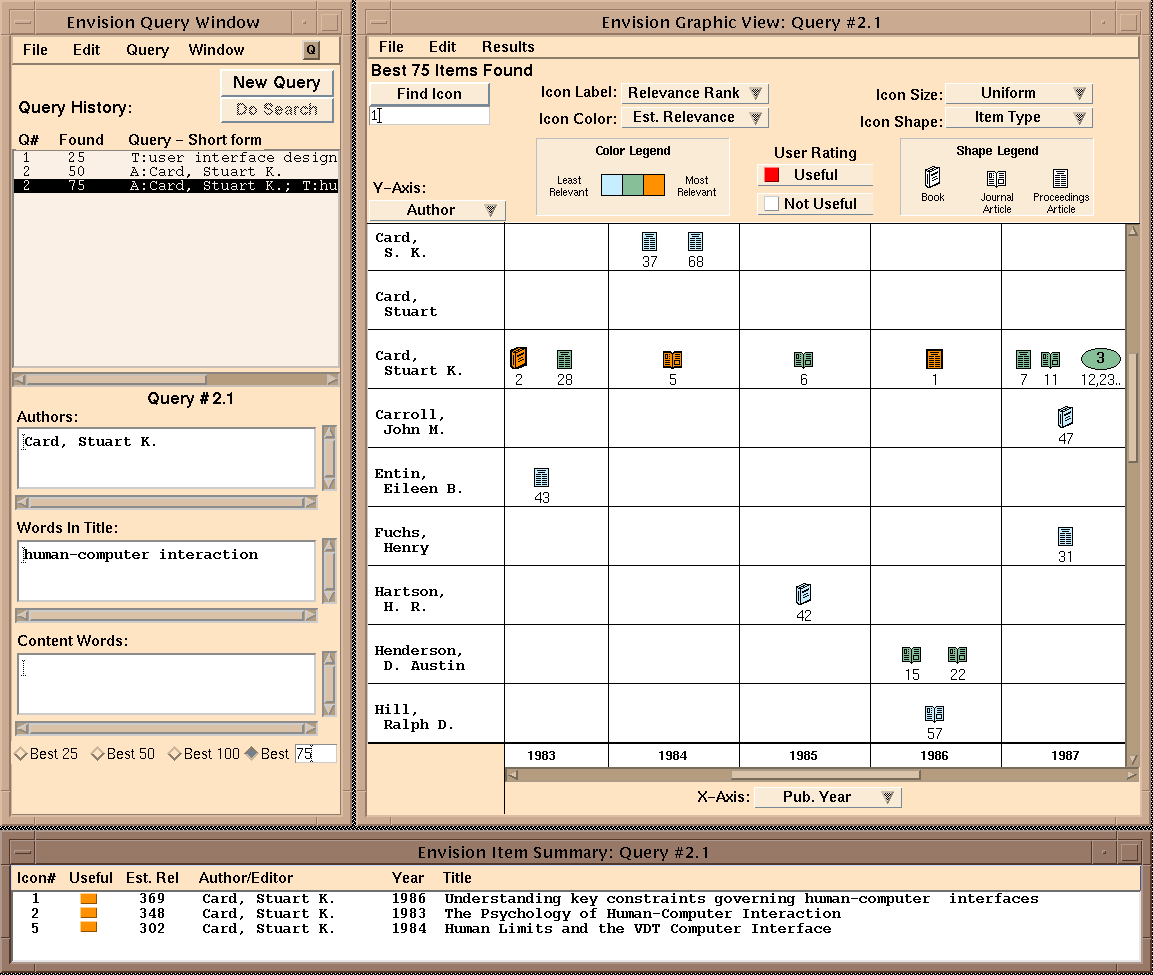
Tabular display is another approach for showing relationships among
retrieval documents. The Envision system [fox93] allows the user
to organize results according to metadata such as author or date along
the X and Y-axes, and uses graphics to show values for attributes
associated with retrieved documents within each cell (see Figure
). Color, shape, and size of an iconic
representation of a document are used to show the computed relevance,
the type of document, or other attributes. Clicking on an icon brings
up more information about the document in another window. Like the
WebCutter system, this view provides few cues about how the documents
are related to one another in terms of their content or meaning. The
SenseMaker system also allows users to group documents into different
views via a table-like display [baldonado97], including a
Scatter/Gather [cutting92] style view. Although tables are
appealing, they cannot show the intersections of many different
attributes; rather they are better for pairwise comparisons. Another
problem with tables for display of textual information is that very
little information can be fitted on a screen at a time, making
comparisons difficult.
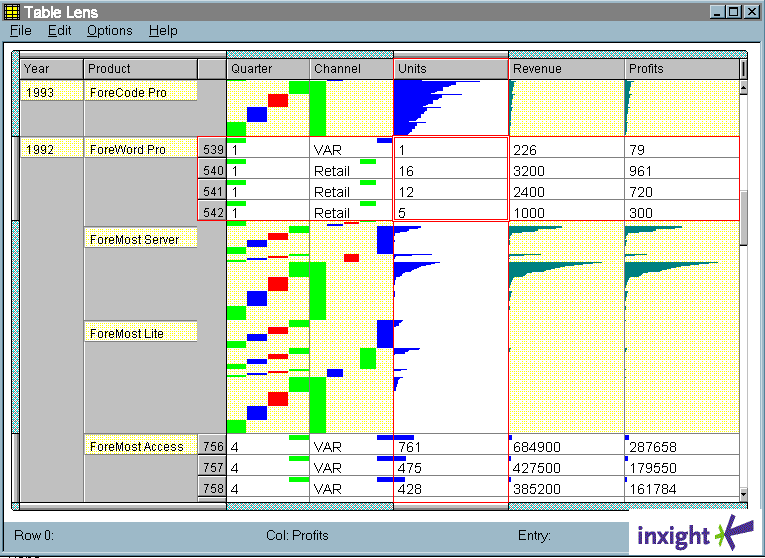
The Table Lens [rao94b] is an innovative interface for viewing and interactively reorganizing very large tables of information (see Figure 10.24). It uses focus-plus-context to fit hundreds of rows of information in a space occupied by at most two dozen rows in standard spreadsheets. And because it allows for rapid reorganization via sorting of columns, users can quickly switch from a view focused around one kind of metadata to another. For example, first sorting documents by rank and then by author name can show the relative ranks of different articles by the same author. A re-sort by date can show patterns in relevance scores with respect to date of publication. This rapid re-sorting capability helps circumvent the problems associated with the fact that tables cannot show many simultaneous intersections.
Another variation on the table theme is that seen in the Perspective Wall [mackinlay91] in which a focus-plus-context display is used to center information currently of interest in the middle of the display, compressing less important information into the periphery on the sides of the wall. The idea is to show in detail the currently most important information while at the same time retaining the context of the rest of the information. For example, if viewing documents in chronological order, the user can easily tell if they are currently looking at documents in the beginning, middle, or end of the time range.
These interfaces have not been applied to information access tasks. The problem with such displays when applied to text is that they require an attribute that can be shown according to an underlying order, such as date. Unfortunately, information useful for organizing text content, such as topic labels, does not have an inherent meaningful order. Alphabetical order is useful for looking up individual items, but not for seeing patterns across items according to adjacency, as in the case for ordered data types like dates and size.