 Transformer or Partitioner
Transformer or Partitioner  Object Streams as in Figure 4.
Object Streams as in Figure 4.
Next: References
Up: On the Construction
Previous: 4 Three Examples
Much of the difficulty in non-trivial information retrieval arises from discrepancies between vocabularies, especially between the two vocabularies that are always present: the vocabulary of the User Query and the vocabulary of the Searchable Index. In practice, several more or less different vocabularies may be present:
A vocabulary problem can arise in the transition from any one of these vocabularies to any other. Vocabulary control (standardization) can occur in document creation, in the creation of document representations, in syndetic structure, and/or in query development. A remedy could, in general, be provided at any of these stages, not necessarily the stage at which the mismatch or ambiguity arises.
As described above, we conceive of all the functional components in a
retrieval system as being either ``objects'', ``transformers'' (representation
makers) or ``partitioners''. Further, as Figure 3 suggests, the components
follow a regular alternating pattern of Object Streams
Transformer or Partitioner Object Streams as in Figure 4.

Figure 4: The common pattern of relationships between all subcomponents of
information selection systems.
The uniformity of this compositionalily of system components suggests that this is a useful level at which to describe the subsystems of information retrieval systems. Further, we argue that if these subsystems contain at least one Partitioner, they can be characterized as complete selection systems. Like the models in Figures 2 and 3, these subcomponents have Input Streams, Transformers or Partitioners (or possibly both) and Output Streams. For example, an ``entry vocabulary'' module in a Query Development subsystem may ``select'' (or ``retrieve'') the correct authorized terms from a system vocabulary. Its inputs would be the User Query, the Source Objects would be the authorized system vocabulary terms, and the might even be External Knowledge in the form of syndetic references. The output of such a subsystem, consisting of the authorized terms that best match the User Query, can be feed into its associated retrieval systems, as illustrated in Figure 5.
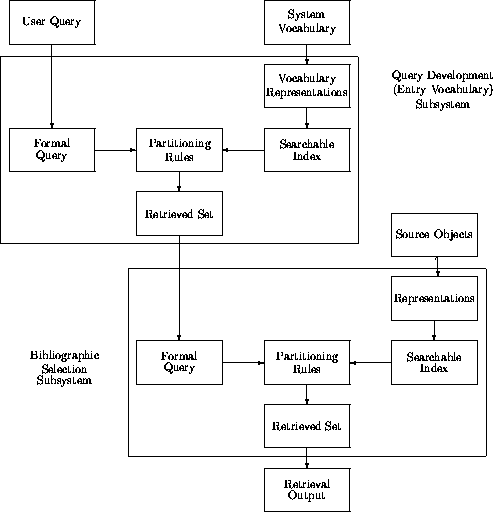
Figure 5: An expanded model which illustrates one way in which retrieval
subsystems can interact within a selection system. The ``Query Development''
component of a bibliographic selection system has been expanded into complete,
separate ``Entry Vocabulary Subsystem''. Scanning (or browsing) authorized
subject headings lists, whether manually or in an automated environment, fits
this model. The system components shown here are only those which are
required.
If accepted, this argument leads to a basic definition of information selection systems: information selection systems can be viewed as one or more interconnected processors (i.e. a transformer or partitioner subsystems), at least one of which is a partitioner, operating on one or more sets of input objects, and producing one or more sets of output objects.
A definition of this nature in turn suggests that one could build very flexible ``workbench'' for information retrieval experimentation out of a number of relatively simple subsystems, themselves built from the components described above, which could be mixed and matched. Given such a basis, several projects immediately suggest themselves, such as comparing alternative functional components on representative test collections with some hope of making reasonable evaluations or comparing of the consequences of trying to remedy vocabulary problems at different stages in the selection process.
A functional analysis of the type presented above provides an framework for the systematic exploration of the range of possibilities in the design of information storage and retrieval systems. It may be that because information storage and retrieval systems have to be complete in order to function at all, there has been an understandable tendency to concentrate on the construction of complete systems and, when comparison has been attempted, to compare complete but complexly different systems or to compare minor variations within a single system. Comparative investigations of retrieval performance, examining the effects of systematic changes in individual components of the system, can be undertaken only with an analytical, modular approach.
Some simple examples of problems and of possible remedies can indicate the variety of options [Buckland n.d.]:
Retrieval problem 1: Insufficient choice of documents. Solution: Add more Source Objects (documents).
Retrieval problem 2: Insufficient basis for appraisal (relevance judgment). Solution: Expand the Representations by copying more of the document and/or adding more description (External Knowledge) from what is known about the document.
Retrieval problem 3: Insufficient indexing for adequate searching. Solution: Expand the Searchable Index by improving the Index Making Rules.
Retrieval problem 4: Retrieval is unreliable because the Searchable Index vocabulary is inconsistent. Solution: Extend the syndetic structure by adding more cross-references expressing relationships between index terms (External Knowledge).
Retrieval problem 5: Clumsy retrieval: Significant information is in the Searchable Index but is not readily usable (e.g. due to output overload). Solution: Extend retrieval capability, possibly by more refined two-stage retrieval: a broad search for high recall followed by a secondary searching (or filtering) of downloaded supersets to improve precision.
Retrieval problem 6: The index vocabulary is unfamiliar to the user. Solution: Provide an entry vocabulary module to the query development module in order to modify the vocabulary of the Formal Query.
In each case a different module provides the location for a plausible solution. For a systematic examination of these issues a detailed functional analysis of information selection systems is needed. Gross comparisons of two substantially different entities cannot provide the analytical power of controlled comparisons based on the systematic variation of individual components.
This functional analysis provides a path away from the arguments that used to characterize information retrieval in the post-World War II period. Any relatively complete functional analysis of information storage and retrieval should provide a basis for the mapping of research and development activities. We suggest that the following components that have been and remain of most interest in Library Science:
The activities generally referred to information retrieval research have historically tended to emphasize:
Others might prefer to nominate other techniques as being characteristic of these streams of research and development, but any realistic mapping on to a general framework of information storage and retrieval theory is likely to reveal how complementary rather than contradictory these interests are. There is a difference in emphasis: the former tending to emphasize quality of data, consistency, and expert human intervention; the latter, exploring efficient algorithmic approaches to large volumes of data. Neither approach alone can provide a complete approach to selection systems in theory or in practice.
This work was partially supported by the United States Department of Education Higher Education Act Title IID grant #R197D00017, Prototype for an Adaptive Library Catalog. We are grateful for the comments of Clifford A. Lynch and Patrick Wilson.