
This paper appears in the proceedings of 20th Annual International ACM/SIGIR
Conference, Philadelphia, PA, July 1997.
Marti A. Hearst Chandu Karadi Xerox PARC School of Medicine, M121 3333 Coyote Hill Rd Stanford University Palo Alto, CA 94304 Stanford, CA 94305 hearst@parc.xerox.com
karadi@leland.stanford.edu
This paper introduces a novel user interface that integrates search and browsing of very large category hierarchies with their associated text collections. A key component is the separate but simultaneous display of the representations of the categories and the retrieved documents. Another key component is the display of multiple selected categories simultaneously, complete with their hierarchical context. The prototype implementation uses animation and a three-dimensional graphical workspace to accommodate the category hierarchy and to store intermediate search results. Query specification in this 3D environment is accomplished via a novel method for painting Boolean queries over a combination of category labels and free text. Examples are shown on a collection of medical text.
In the Proceedings of the Twentieth Annual International ACM SIGIR Conference, Philadelphia, PA, July 1997, to appear.
There exist today many large online text collections to which category labels have been assigned. MEDLINE, a huge collection of biomedical articles, has associated with it Medical Subject Headings (MeSH) consisting of approximately 16,000 categories [ Lowe & Barnett1994]. The Association for Computing Machinery (ACM) has developed a hierarchy of approximately 1200 category (keyword) labels ( http://www.acm.org/class/1991/cr91.html). Yahoo!, one of the most popular search sites on the World Wide Web, organizes web pages into a hierarchy consisting of thousands of category labels ( http://www.yahoo.com). And traditional online bibliographic systems have for decades assigned subject headings to books and other documents [Svenonius1986].
The meanings of the category labels differ somewhat among collections, but usually they are intended to help organize the documents and to aid in query specification. Unfortunately, as reported in a recent paper from the library sciences community, users of online bibliographic catalogs rarely use the available subject headings [Drabenstott & Weller1996]. These and other authors put much of the blame on poor (command line-based) user interfaces which provide little aid for selecting subject labels and force users to scroll through long alphabetic lists.
Although many researchers have investigated techniques for automatically augmenting word-based queries with category labels, there has been surprising little research on advanced user interfaces for browsing in and selecting from large category hierarchies for the purposes of information access. There has been still less on how to integrate category hierarchies with retrieval results, and work is especially lacking in the support of search when multiple categories have been assigned to each document.
This paper describes an interactive user interface that integrates
search and browsing of very large category hierarchies with their
associated text collections. The prototype system, called the
Cat-a-Cone, uses existing 3D+animation interface components, applied
in a novel way, to support browsing and search of text collections and
their category hierarchies.
(Cat-a-Cone integrates category hierarchies
into ConeTrees. The name is almost a homophone of
catacomb, a word whose secondary definition is a complex set of
interrelated things.)
A key component of the interface is the separation of the graphical representation of the category hierarchy from the graphical representation of the documents. This separation allows for a fluid, flexible interaction between browsing and search, and between categories and documents. It also provides a mechanism by which a set of categories associated with a document can be viewed along with their hierarchical context.
Another key component of the design is assignment of first-class status to the representation of text content. The retrieved documents are stored in a 3D+animation book representation [Card et al.1996] that allows for compact display of moderate numbers of documents. Associated with each retrieved document is a page of links to the category hierarchy and a page of text showing the document contents. The user can ``ruffle'' the pages of the book of retrieval results and see corresponding changes in the category hierarchy, which is also represented in 3D+animation. All and only those parts of the category space that reflect the semantics of the retrieved document are shown with that document.
In summary, this interface is designed to exhibit the following features (see Figure 1):
Our interaction model is similar to that described in [Agosti et al.1992]. These authors define a two-level architecture for linking documents and their ``auxiliary data''. However, the implementation and that used in a followup study [Belkin et al.1993] use a text-based interface which does not provide most of the affordances listed above. [Ingwersen & Wormell1986] also describes a text-based interface that allows the user to alternate between free text and thesaurus terms.
Before describing the interface in more detail, Section 2 discusses our view of the role of categories in information access and related work. Then Section 3 describes the Cat-a-Cone and examples of its use, Section 4 discusses other graphical information access interfaces, and Section 5 summarizes the paper.
Figure 1: The Cat-a-Cone interface. Shown are the
results of a search on category labels Mastectomy and
Radiation Therapy in conjunction with the text word ``lumpectomy'' on
a breast cancer subset of the MEDLINE collection. A ConeTree displays
category labels and a WebBook shows retrieval results. The lefthand
page shows the title and the category labels associated with the
document. The righthand page shows the abstract associated with the
document.
Books that are the results of previous searches are stored in the
workspace on the bookshelf, thus acting as a memory aid.
All and only those categories (and their ancestors) present in the current document are displayed in the category hierarchy. When the user clicks on a category label on the lefthand page, the corresponding category label in the ConeTree is rotated to the foreground and the labels of its ancestors are highlighted. When the user ``turns'' the pages of the book, the subtrees of the category hierarchy rotate, expand, and contract appropriately (categories that were present on the previous page and are present on the new page remain constant, categories that were on the previous page but are not on the new page are pruned away, and new categories that were not on the previous page but are on the new page are expanded out).
In this section we discuss what is meant by category labels in this work, in particular contrasting categories with other kinds of meta-information and with thesaurus terms. We also motivate our design decisions by first describing results of recent experiments in improving document ranking by automatically combining category labels with free text, and then discussing the special considerations that accompany the search and display of documents to which multiple categories have been assigned.
Most documents have some kinds of meta-information associated with them - that is, information that characterizes the external properties of the document, that help identify it and the circumstances surrounding its creation and use. These attributes include author(s), date of publication, length of document, publisher, and document genre. Several research groups are exploring issues associated with user interfaces for exploiting this kind of information, usually employing variations on a table format, e.g., [Fox et al.1993, Baldonado & Winograd1997].
By contrast, this paper focuses on category sets that have been assigned in an attempt to characterize the content or meanings found within the text of documents. Content-oriented category sets are difficult to depict graphically because they are abstract and there are potentially more meaningful combinations of content categories than external meta-information.
Many researchers have investigated automatic thesaurus creation, most often using word co-occurrences, e.g., [Crouch1990, Ruge1991, Evans et al.1991, Grefenstette1994]. Thesaurus terms are related to category labels in information access systems, in that both kinds of information are used to improve recall. However, there are several important differences between the two.
Category labels are used to classify documents' contents according to general subject areas and other semantic attributes. Categories are instantiated by the set of documents they are assigned to, and are represented by their labels. These labels are used as a kind of meta-information, and typically category labels are matched against other labels when used in search.
By contrast, thesaurus terms are usually used as alternative ways to express a concept. Thesaurus terms can compensate for the occasions when the actual words used by the user in the query do not match the way the concepts are expressed in the document. When a user adds terms to the query from a thesaurus (or from relevance feedback for that matter), this usually means adding the actual words from the thesaurus into the query in hopes that they will appropriately match words in the documents of interest. Thesaurus terms are typically represented by the words themselves,
This distinction does not hold in all cases. Techniques such as Latent Semantic Indexing [Deerwester et al.1990, Schütze1993] map the meaning of one set of words to another by means of a vector representation. Thus it attempts to find general themes which could be thought of as categories although the representation is nonstandard. However, thinking of the terms as thesaurus terms rather than category labels tends to influence how they are used in the user interface.
Library catalog systems have long provided categorization information in the form of subject headings. Researchers have reported that these kinds of headings often mismatch user expectations [Svenonius1986, Lancaster1986]. However, there is also evidence that when such subject heading information is combined with free text search, results are improved over using either categories or free text alone, although usually these improvements are small [Markey et al.1982, Henzler1978, Lancaster1986]. Most of this work was done in the bibliographic context and did not employ modern user interface technology.
Studies on the biomedical category set, MeSH, usually do not achieve strong improvements on MEDLINE searches with automatic addition of category labels over non-MeSH searches [Srinivasan1996a]. Only very small improvements were found in two studies [Hersh et al.1994, Aronson et al.1994] on a larger collection (using the Metathesaurus, a much larger hierarchy than MeSH [Schuyler et al.1993]). Larger improvements were found in another study [Yang & Chute1994], but under the assumption that a new query will match against a query that had already been seen and analyzed extensively with training examples.
However, recent careful studies [Srinivasan1996b, Srinivasan1996c] have shown that if done appropriately, adding in MeSH terms can lead to significant improvements in precision and recall simultaneously, even over an initial high baseline. Importantly, these improvements were not found by using the standard technique of automatically mapping natural language queries into semantically equivalent MeSH terms, as is done with most attempts to automatically improve ranking with category labels.
Rather, improvements were found by retrieving documents based on the free-text version of the query, taking the top-ranked documents for relevance feedback, and adding to the query the MeSH category labels that appeared in the top-ranked documents. This suggests that first finding some good example documents, and then examining the category labels assigned to them, and using these to revise the query is a more effective way to improve rankings via category labels. This is precisely the kind of interaction that our framework is designed to support.
Many graphical user interfaces for text collections place documents within one point in semantic space, usually based on some measure of inter-document similarity (see Section 4). We assert there is a problem with assuming that documents can be placed into a single category or a single point in semantic space. Although real-life objects can (arguably) be assigned one place in a taxonomy (a truck is a kind of vehicle), the content of text is usually not so simply classified.
Consider for example a biomedical journal article entitled Fear of Recurrence, Breast-Conserving Surgery and the Trade-Off Hypothesis. This article has been manually assigned the MeSH category labels: (Items in parentheses represent subheading modifiers for the main category labels. Our subset of MEDLINE documents have on average eight category labels assigned to them.)
The article discusses a statistical study of the effects of a patient's fear of recurrence of breast cancer after a partial mastectomy versus the improved self image the patient has from retaining part of the breast. Thus, at a high level the human categorizers have placed the article into the semantic space at the intersection of Surgery, Statistics, and Psychology, since all three areas help characterize the complex subject matter of the document. At a more detailed level, the document content rests along the axes of a contrast between particular surgical procedures, a particular kind of statistical study and analysis, and the measurement of a particular psychological attribute.
When documents are clustered or grouped according to overall similarity, the distinctions about which axes they are similar on are not visible to the user. Placing the example document within a cluster of others might be done because any subset of the topic areas discussed were held in common. A cluster-based representation can be useful for some purposes, such as getting an overview of a collection's contents, but a user interface that shows the inter-relations among documents according to their category labels (or in general, according to orthogonal semantic attributes) allows the user an alternative view of document similarity.
Most interfaces that depict category hierarchies graphically do so by associating a document directly with the node of the category hierarchy to which it has been assigned. For example, clicking on a category link in Yahoo! brings up a list of documents that have been assigned that category label. Conceptually, the document is stored within the category label. When navigating the results of a search in Yahoo!, the user must look through a list of category labels and guess which one is most likely to contain references to the topic of interest. A wrong path requires backing up and trying again, and remembering which pages contain which information. If the desired information is deep in the hierarchy, or not available at all, this can be a time-consuming and frustrating process.
The MeSHBROWSE system [Korn & Shneiderman1995] allows users to interactively browse a subset of semantically associated links in the MeSH hierarchy. From a given starting point, clicking on a category causes the associated categories to be displayed in a 2D tree representation. The interface has the space limitations inherent in a 2D hierarchy display and does not provide mechanisms for search over an underlying document collection.
Internet Grateful Med ( http://igm.nlm.nih.gov:80/) is a World Wide Web-based service that allows an integration of search with display and selection of MeSH category labels. The site is designed to support many simultaneous users and is constrained by the limitations of HTML. After the user types in the name of a potential category label, a long list of choices is shown in a page. To see more information about a given label, the user selects a link (e.g., Radiation Injuries). The current context is lost, and a new web page appears showing the ancestors of the term and its immediate descendants. If the user attempts to see the siblings of the parent term (Wounds and Injuries) then the context is changed again. Radiation Injuries appears as one of many siblings and the context of its children is lost. To go back to the previous list of choices, this page is obliterated.
One recent interface focuses on displaying faceted category sets [Allen1995]. In this work, hierarchical category labels corresponding to the Dewey Decimal system are shown indented in a scrollable window, in a focus-plus-context manner similar to that used in the Superbook table of contents [Egan et al.1989]. All documents that have been assigned a selected category are listed in another scrollable window. When the user issues a search, all categories that have a title with a hit in them are displayed in a scrollable window, with a number showing how many hits fall into each category. Thus this interface does not support display of multiple labels per document.
Our earlier work [Hearst1994] emphasized many of the same points as in the present work. However, the interface for choosing and displaying categories could not support hierarchies of categories and did not provide a good mechanism for viewing the retrieved documents. The Cat-a-Cone interface represents a dramatic improvement.
We assert that separating the documents from the category hierarchy can open the door to more powerful search and display strategies, especially for collections in which documents have multiple category assignments.
Our approach consists of three main components. The first is a better representation of the category space, the second is a separate, compact representation of retrieved documents, and the third is a model of interaction that makes use of these visualizations in novel ways. The instantiation of these ideas is in a prototype interface that makes use of particular visualization technologies, but does not exclude using alternative technologies that support the same or similar functionalities.
Our prototype implementation (written in Common LISP, running on Silicon Graphics IRIX machines), makes use of the ConeTree 3D+animation visualization from the Xerox PARC Information Visualizer (IV) [Robertson et al.1993]. (Processing speeds and monitor quality are increasing rapidly enough to make general availability realistic within the next few years.) The ConeTree allows for the display of a very large category hierarchy all in one window. Those categories that are farther away and less legible can be rotated to the foreground with a simple click on the leftmost (highest ancestor) category label. The interface allows users to choose from menus, or gesture-based ``gardening'' commands for growing and pruning subportions of the hierarchy, as well as keyboard accelerators and traditional buttons on the ``desktop'' portion of the workspace for specifying searches.
If a label is terminated with a triangle, this signals the existence of a subtree. The user can expand the category one level down by a right-drag gesture, or can select the node with the left mouse button and then click on the ``Grow SubMeSH'' button on the workspace to expand the entire subtree (this button's label and functionality toggles depending on the state of the selected label).
The examples in the following subsections are drawn from a subcollection of MEDLINE abstracts on breast cancer. This subcollection was further narrowed to include only those 403 documents that contained the word lumpectomy in their title or abstract (the equivalent MeSH term is Mastectomy, Segmental).
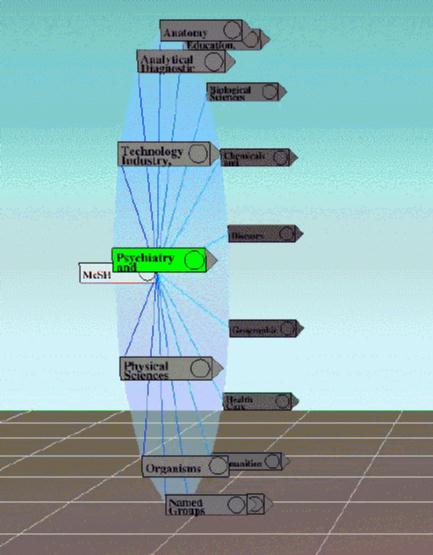
Figure 2: The top-level representation of the MeSH
hierarchy as a search starting point.
Search interfaces must provide users with good ways to get started. [Shneiderman1996] advocates a model of: first overview, then zoom and filter, then details, and repeat. In terms of the overview, an empty screen does not provide a good starting point. On the other hand, the contents of the entire hierarchy can be overwhelming, even if it can be made to fit in one window. The model of interaction used here allows for several different starting points and interaction sequences.
One starting point shows all of the top level categories initially, and allows the user to control the subsequent expansions (see Figure 2). The user can select one label to expand in detail, revealing all of its descendants rather than having to navigate laboriously through many pages to see all of the subtrees. If this is still too overwhelming, the user can select a few nodes and issue the command ``prune others'' to view a smaller space. Or the system can be programmed to automaticaly expand subtrees to a depth that has been determined by user studies to be most comprehensible.
An alternative starting point is to have the user type in a category label and see which parts of the hierarchy match or partially match that label. The user can then expand and explore other nearby regions.
As a final Cat-a-Cone starting point type, the user can type in free text, causing the system to retrieve documents containing those words in their titles or abstracts. The user can then view the category labels associated with the retrieved documents. This kind of interaction should be useful in analogy with the findings of the experiments of [Srinivasan1996b, Srinivasan1996c] discussed above, in which good MeSH categories were associated with documents highly ranked against the free-text query.
For example, after a search on the category Mastectomy the system retrieves an article that has a link to Survival Analysis, a category which the user might not have known in advance. The user can then decide to delve more deeply into this topic by issuing a search on this category label, another category label, and one free-text word, yielding the book of Figure 1. This book in turn can aid the user in discovering that the MeSH hierarchy has a set of category labels pertaining to psychological issues, including Emotions.
When indexing new MEDLINE citations, indexers are instructed to use the most specific MeSH term available [Lowe & Barnett1994]. Often these low-level categories are meaningless to a patient or non-specialist. The context-preserving display of ancestor and sibling information provided by this representation can help the user see the general meaning of a term. For example, the category label Doxorubicin is the name of a chemical, and this is indicated by its ancestor labels.
The Cat-a-Cone also makes use of a modification of WebBooks from the Web Forager project [Card et al.1996], an extension of the Information Visualizer project. After a set of documents has been retrieved (in response to a query on free text and/or category labels), the documents are organized into a ``book'' of pages (see Figure 1). The lefthand page contains the document's title and the list of category labels associated with that document. The righthand page shows the abstract and/or content of the documents (the pages are scrollable).
The cover of the book shows the query responsible for producing the retrieval results. When the book is closed and is the selected focus, the ConeTree can show a representation of all of the categories that have occurrences within the pages of the book. Note that since multiple categories have been assigned to each document, the book will in general contain many more category labels than were present in the original query. Only those parts of the hierarchy that contain categories that are in the book (and their ancestors) are shown automatically; the rest of the hierarchy is pruned away. The user is able to expand or contract any part of the hierarchy at any time.
When the user opens the book, the ConeTree is automatically modified to show only those parts of the hierarchy whose categories appear in the document on the current page. The labels themselves are outlined in blue and the ancestors are shown without outline. This representation shows the space of concepts in which the document resides. When the user flips through the pages of the book, the representation of the tree adjusts accordingly. The use of animation helps retain the context of the category set. Often many category labels are shared among the book's retrieval results, so only a few offshoots of the hierarchy grow or are pruned as the user flips through the retrieved pages. The animation helps the user retain context, showing which parts of the category space differ from document to document.
Since the user can store the book away and reopen it at any time (making use of the workspace capabilities of IV) there is less reason to worry about getting ``lost'' or forgetting what happened in a previous session, because the retrieval results can be stored away and reused.
As currently described, the interaction between the category hierarchy and the retrieved documents is not entirely two-way: clicking on category labels does not influence the behavior of the retrieval results. This choice was made in part because there is a many-to-one mapping of category labels to book pages. However, the model could be altered as follows: clicking on a label causes the page of the book to turn to the next article containing that category label, if such an article exists.
In order to help further explain the retrieval results, other information access interface ideas can be incorporated into this representation. For example, we plan to place a TileBars [Hearst1995] representation of the retrieval results into the first page of the book, which can be pulled out and viewed alongside the rest.
Research suggests that users often want to search on an ``exploded'' part of the MeSH hierarchy to improve recall [Lowe & Barnett1994]. In effect, they wish to specify a conjunction of disjunctions over category hierarchies, that is, require that at least one representative from each of a set of concepts be present in the retrieved documents. Our initial simple approach to query specification is to have the selection of the yellow circle on a category label indicate a disjunct of all of that category's descendants, inclusive. A conjunction is imposed over all selected subtrees. This approach is simple, but for queries such as (hand OR foot) AND arthritis it requires the user to select higher up in the anatomy subtree than desired.
For this reason, we have devised a novel scheme for specifying Boolean queries using the 3D environment. The user selects colors from a ``palette'' and ``paints'' subtrees with these colors, where each color representing members of a disjunction, and different colors indicate different components of a conjunction. Additionally, free text search terms are typed into entry lines of corresponding colors. The users are instructed to think of the query in terms of colors rather than as a Boolean expression. For example, a user can specify a conjunction of disjunctions while thinking something like ``I want documents that contain at least one green, at least one yellow, and at least one blue category or word.'' The retrieval results do not need to employ a strict Boolean filter; a quorum ranking strategy [Salton1989] can be used instead. In this scheme, different colors receive different weight, and those documents represented by hits on more colors are ranked higher than those with fewer colors.
This query specification scheme thus stays within the object-centric paradigm and provides a simple way for users to link subsets of category labels and free text in complex Boolean expressions (with NOT represented by red).
Several approaches map documents from their high dimensional representation in document space into a 2D representation in which each document is represented as a dot or other small glyph. The functions for transforming the data into the lower dimensional space differ, but the net effect is that documents are placed at one point in a scatter-plot-like representation of the space, and users are meant to detect themes or clusters in the arrangement of the glyphs. These systems include BEAD [Chalmers & Chitson1992], ThemeScapes [Wise et al.1995], and the Galaxy of News [Rennison1994]. Other systems, e.g. [Cutting et al.1992, Maarek & Wecker1994, Allen et al.1993] display inter-document similarity hierarchically. The systems of [Fowler et al.1991] and IR [Thompson & Croft1989] display retrieved documents in networks based on interdocument similarity.
Systems such as VIBE [Korfhage1991] and the InfoCrystal [Spoerri1993] ask the user specify the query in terms of k words (although category labels could be used instead) where k is a small number. They then display, for each subset of the k categories, the number of documents that contain that subset of words. These systems show the categories in a graphical concept space, and do not provide a mechanism for choosing which of a large number of words or categories to choose from, nor do they suggest new words or categories, nor associations among category labels, and they do not introduce methods for associating the text of the documents with new words or categories.
The Lyberworld system [Hemmje et al.1994] makes use of a ConeTree but uses it quite differently than the Cat-a-Cone. Lyberworld uses the ConeTree to display the navigation path generated by a sequence of search steps, placing the documents associated with the results of the search at the first level of the hierarchy, expanding on the words of a given document's node at the next level, and repeating.
Some researchers, e.g.,[Pedersen1993, Carpineto & Romano1996], have employed a graphical depiction of a lattice for query formulation, where the query consists of a set of constraints on a hierarchy of categories (actually, semantic attributes in these systems). This is one solution to the problem of displaying documents in terms of multiple attributes; a document containing terms A, B, C, and D could be placed at a point in the lattice with these four categories as parents. However, if such a representation were to be applied to retrieval results instead of query formulation, the lattice layout would in most cases be too complex to allow for readability.
In the AIR/SCALIR interface [Rose & Belew1991] a connectionist network determines in advance a set of terms that characterize documents from a collection of bibliographic records. The term nodes are connected to the document nodes via edge links, so the user can see which documents are associated with each important term. If there are a large number of links between associated terms and documents, or if the links are not neatly organized, the relationships will be difficult to discern.
Finally, Kohonen's feature map algorithm has been used to create maps that graphically characterize the overall content of a document collection or subcollection [Lin et al.1991, Chen et al.1997]. The regions of the 2D map vary in size and shape corresponding to how frequently their corresponding themes occur in the collection. Regions are characterized by single words or phrases, and adjacency of regions is meant to reflect semantic relatedness of the themes within the collection. If a document is strongly associated with the region according to the training of the feature map, its title can be viewed via a pop-up window over that region; documents can be associated with more than one region.
A recent evaluation [Chen et al.1997] compared the Kohonen feature map representation on a browsing task to that of Yahoo!. The results found that some users expressed a desire for a visible hierarchical organization, others wanted an ability to zoom in on a subarea to get more detail, and some users disliked having to look through the entire map to find a theme, desiring an alphabetical ordering instead. Many found the single-term labels to be misleading, in part because they were ambiguous (one region called ``BILL'' was thought to correspond to a person's name rather than counting money). The subjects like the ease of being able to jump from one area to another without having to back up as is required in Yahoo! and liked the fact that the maps have varying levels of granularity. (The authors concluded that this interface is more appropriate for casual browsing than for search.)
These results all support the design decisions made in the Cat-a-Cone. Hierarchical representation of term meanings is supported, so users can choose which level of description is meaningful to them. Furthermore, they can view different levels of description simultaneously, so more familiar concepts can be viewed in more detail, and less familiar at a more general level. An alphabetical ordering of the categories coupled with a regular expression search mechanism allows for straightforward location of category labels. Retrieved documents are represented as first-class objects, so full text is visible, but in a compact form. Category labels are disambiguated by their ancestor/descendant/sibling representation. Users can jump easily from one category to another and can in addition query on multiple categories simultaneously (something that is not a natural feature of the maps). The Cat-a-Cone has several additional advantages as well, such as allowing a document to be placed at the intersection of several categories, and explicitly linking document contents with the category representation.
The Cat-a-Cone interface allows for fluid two-way interaction between selection of category labels for search and display of multiple category labels within retrieval results. The ConeTree provides easy selection of subparts of the category hierarchy, to help users understand unfamiliar terms and usages of ambiguous terms by seeing their contexts. The book-based representation of the retrieval results with the corresponding display of multiple subparts of the category hierarchy helps show which categories are a part of the results, what these categories mean, and which new categories might be useful to search on.
Although this is a simple combination of simple ideas, it seems to produce a powerful, intuitive and original way for users to use large category hierarchies to aid them in query specification and understanding of retrieval results. In future work we plan to evaluate the interface using as subjects breast cancer patients and clinicians.
This kind of interaction should also be useful for other tasks, for example, helping authors of articles for ACM publications choose which category labels to assign to their documents. The user can tell the system to find documents whose textual contents are similar to their new document's, and then examine the resulting category hierarchy.
The ConeTree as currently implemented does not satisfy fully the needs of the design. For example, the system should reformat subtrees when space becomes available as a consequence of pruning away other subtrees. Additionally, a recent study shows that fisheye, variable zoom algorithms work better than full zoom algorithms for navigating networks [Schaffer et al.1996], and an improved facility for focus-plus-context of this kind could be used to help direct user attention. Subtrees should be easily ``pulled off'' and stored for later use. Finally, the display should reflect the frequency of the categories for a given retrieval result with a visual analogue such as ``Read Wear'' [Hill et al.1992] or using a Kohonen feature map [Lin et al.1991] as an overview of the highest-level categories.
We view information retrieval as a complex task that requires many different tools. Support for category browsing and search is one important capability, but by no means solves the entire problem. This interface must be combined with others to create an effective information seeking system.
Karadi was supported in part by a Medical Scholars Grant from Stanford Medical School. We would like to thank Larry Fagan, Bill York, and Stu Card for their help with and encouragement of this work. Additional figures can be found at http://www.parc.xerox.com/ia .