Next: 4 Three Examples
Up: On the Construction
Previous: 2 A Basic Model
This illustrative description of a complete retrieval system provides a basis
for further analysis. We do not claim that all retrieval systems are as
depicted in Figure 2. Some are less complete, others more complex, but we do
suggest that all retrieval systems could be depicted using these functional
components. Not all components are always present. Some components may be
present multiple times. The assumption with which we proceed is that in all
cases the User Query, Formal Query, Source Objects, Representations,
Searchable Index, Partitioning Rule, a Retrieved Set (possibly empty) and
Retrieval Output (also possibly empty) are always present in any
functional information selection system. The Representations, being derived
from some combination of Source Objects and/or External Knowledge Sources,
require that at least one or other of the latter must be present as a direct
source input. The other components may be absent or present. We now take a
closer look at the nature of these components.
The minimally complete model in Figure 2 represents a series of data objects,
transformations and partitionings. The Representations are derived from
Source Objects and/or External Knowledge Sources by way of Representation
Making Rules. The Searchable Index is derived from the Representation and the
Index Making Rules, which itself partitions the Representation into index
terms. The Formal Query is a transformation, by way of the Query Development
Rules, of the User Query. The Matching Rule partitions the Representations,
through the Searchable Index and the Formal Query, into the Retrieved Set.
The Retrieved Set may be subjected to a Sorting Rule before becoming Retrieval
Output. These transformations of datasets can be seen as being of two types.
All of the operations (``methods'' in Object Oriented terminology) carried out
in existing information selection systems are either transformations,
i.e. representation making operations, or partitionings,
i.e. rearranging operations. User Queries are transformed into Formal
Queries. Source Objects are transformed into Representations.
Representations are transformed into Searchable Indexes. Representations are
partitioned into retrieved and non-retrieved sets. A sorted Retrieved Set is
transformed (i.e. copied) to Retrieval Output.
A rather overlooked feature of retrieval systems is the practice, common in
boolean bibliographic retrieval systems, of re-ordering (applying a
Sorting Rule to) a retrieved subset (usually alphabetically by author) prior
to display or other form of output. Conceptually, a ``sort'' instruction is
brought to bear on any set of retrieved records -- sort by author, for example
-- which is specified either ad hoc or by default. This component (a Sorting
Rule applied to the Retrieved Set) of the retrieval process is functionally
equivalent to the retrieval (Matching) rule. The only significant difference
is that the Sorting Rule operates only on a subset of records, i.e. those
previously partitioned off by the retrieval mechanism.
The Query Development Rules component serves to transform a user's information
need, or query, into a representational form suitable for submission to the
Matching Rule. This role may be performed by a human intermediary and
involve complex interaction and negotiation with the user (the ``reference
interview'' [Jennerich 87]). Where query development is performed
algorithmically it most often appears to have two parts:
- Query normalization transforms the query into a form expected to fit
the matching process, e.g. the forms ``Jane Doe'' and ``Doe, Jane''
need to be processed into a form of surname and forename that the
matching process can handle. This, then, is a matter of using rules
to the create and a version (a representation) of the user's query
that will be acceptable at the next stage.
- A different kind of query development occurs in the process,
sometimes referred to as ``entry vocabulary'', by which terms used in
the user's query are replaced by terms used in (or expected to be in)
the system's Searchable Index. It is, especially, a matter of
substituting an ``authorized'' index term for a user's term that is
not used in the index (e.g. converting ``jail'' and ``gaol'' to
``prison'') or with the one or more terms that appear to be the
closest approximation. As use of the term ``substitution'' indicates,
this is conceptually a one-to-one mapping or ``transformation''
process. However, it can also be seen as a ``matching'' process, that
is, functionally, another, separate retrieval (i.e. sorting and
ordering) process: Find and separate out the term(s) that most closely
(or most likely) match the term(s) in the user's query. Like a
``known item'' search for a book it may often be thought of as a
one-to-one correspondence, but it is not necessarily so. It may be a
one-to-many or a probabilistic process. This, then, is another case
of using a partitioning procedure to select some subset from a
predetermined set.
``Entry vocabulary'' procedures in the form described above are not yet
commonly provided though we expect them to become so. However, two other
forms are common:
- Where the user's query is expressed by selection from menus, the
menu options are the system's ``terms''
- Where the browsing of index terms is supported, a user's query
generates a selection (partitioning) of related system terms,
retrieving only the Searchable Index or from a separately stored
thesaurus. Selecting from this partitioned subset can then generate a
new query.
As with Query Development, matching (partitioning) processes can occur in
Representation Making. The process of deriving a Representation from a
Source Object, as noted above, can be seen as having two components. In some
cases the representation will be a copy of the object, possibly modified by
technical constraints in the system (e.g. accents lost in representing a
foreign text or loss of color or resolution in a copy of an image). In other
cases, the representation may be a description of the source object (e.g. in a
catalog composed of textual descriptions of non-textual objects.) The
representation could be a combination of copy and of description (as in
library catalog records which include fragments such as title copied from the
original and added description such as subject headings).
In the terminology that we have adopted the creation of Representations is
primarily and obviously Representation Making. This is clearly the case with
any portion of the representation that is a copy derived from the Source
Object. An algorithmic representation (such as automatically generated word
occurrence vectors) is derived in the same way. It may no longer be a
recognizable copy, but it is a descriptive representation of the source
object. The Representation may also derived from a copy of a description from
some other source such as an existing database descriptions (as in the
bibliographic utilities heavily used in creating library catalogs) or be an
expression of what some human indexer's perception.
Nevertheless, an ordering process may occur within Representation Making if
and when some part of the Representation is constrained by a controlled
vocabulary. It is desirable to select only terms acceptable to the system,
whether done by machine or by human. This activity is functionally very
similar to entry vocabulary control.
A significant problem arises in retrieval systems with large, long term stores
of Representations when changes are made to the Representation Knowledge
Source or to the Representation Making Rules. Should these changes be applied
retroactively to previously processed representations? Is it feasible?
Notoriously, library card catalogs were often not updated retroactively,
although in some cases, such as changed names or terms, the consequences could
be mitigated by changes to the syndetic structure in the Searchable Index
(e.g. by adding "see also" links from new to old forms).
There are no grounds to limit retrieval to these two stages: partitioning,
then (possibly) ordering. It is a trivial matter to imagine more than two
stages. Simple boolean retrieval systems lend themselves to a series of
progressively modified searches by allowing prior queries to be successively
modified (e.g. with the addition of further limits in the form of boolean ANDs
or NOTs). One might start by selecting records containing, say, the subject
keyword NAPOLEON; the retrieved set, especially if large, might then be
partitioned (or filtered or sorted) by language, to bring forward items in
English; each subset record might be subsorted by date and/or by title and/or
by author. Such a two-stage strategy is one answer to the difficulty of
achieving high precision as well as high recall [Buckland et al 93]. A search
intended to achieve high recall can be followed by a different kind of search
of the initially retrieved set in order to produce a second retrieved set with
better precision [Buckland & Gey 93]. More generally, information retrieval is
ordinarily an iterative process in that the result of one matching is often
the basis for a secondary or modified search with another query that modifies
or replaces an earlier one.
Our examination of the basic illustrative model depicted in Figure 2 has led
to the conclusion that each of different components can be viewed as being
composed of either data objects, or one of two different processes which we
have called ``transforming'' (representation making) or ``partitioning''
(selecting or ordering). If accepted, this view has interesting consequences:
- At a theoretical level it indicates that information storage and
retrieval systems are composed functionally of sequences of just two
kinds of activity: Transformations (the deriving of new versions) of
data and Partitioning (sorting, ordering, selecting) of subsets from
larger sets of data objects.
- We established above that the partitioning function (alias matching,
ordering, selecting, sorting) does not occur only once, but, except in
very simple information storage and retrieval systems, can be expected
to occur repeatedly.
There are several different implementable procedures (techniques) for
partitioning and transforming. At a technical level, this more abstract
formulation creates, in effect, an invitation to experiment by substituting
alternative partitioning and/or transforming techniques at each point at which
any ordering occurs, and a framework within which to evaluate such work.
Figure 3 offers a more abstract restatement of
Figure 2 in terms of these two functional types.
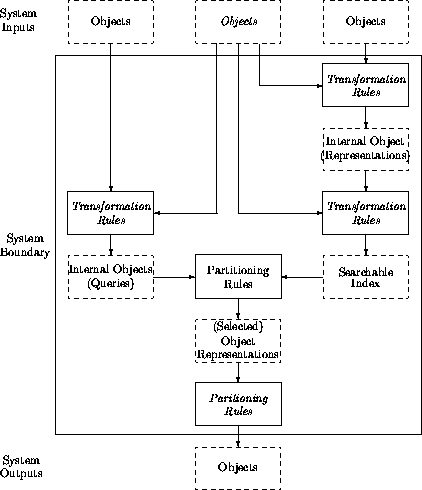
Figure 3: A
minimally complete abstract model of information retrieval (selection)
systems. Solid boxes indicate processes (``transformers'' or
``partitioners''), dashed boxes data objects. Italics indicate optional
components. Arrows show flows (or streams) of information objects. Note that
the only required ``process'' is the central partitioning rule, and that
subcomponents are formed by patterns of Objects  Process
Process
 Objects.
Objects.
Next: 4 Three Examples
Up: On the Construction
Previous: 2 A Basic Model