Chapter 1: Introduction

Contents
|
Modern Information Retrieval Chapter 1: Introduction |
Contents |
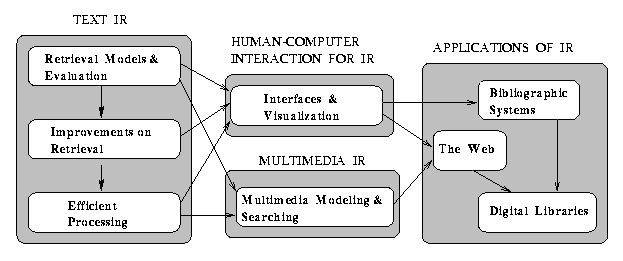
For ease of comprehension, this book has a straightforward structure in which four main parts are distinguished: text IR, human-computer interaction (HCI) for IR, multimedia IR, and applications of IR. Text IR discusses the classic problem of searching a collection of documents for useful information. HCI for IR discusses current trends in IR towards improved user interfaces and better data visualization tools. Multimedia IR discusses how to index document images and other binary data by extracting features from their content and how to search them efficiently. On the other hand, document images that are predominantly text (rather than pictures) are called textual images and are amenable to automatic extraction of keywords through metadescriptors, and can be retrieved using text IR techniques. Applications of IR covers modern applications of IR such as the Web, bibliographic systems, and digital libraries. Each part is divided into topics which we now discuss.
![[*]](cross_ref_motif.gif) . These eight topics are as follows.
. These eight topics are as follows.
The topic Retrieval Models & Evaluation discusses the traditional models of searching text for useful information and the procedures for evaluating an information retrieval system. The topic Improvements on Retrieval discusses techniques for transforming the query and the text of the documents with the aim of improving retrieval. The topic Efficient Processing discusses indexing and searching approaches for speeding up the retrieval. These three topics compose the first part on Text IR.
The topic Interfaces & Visualization covers the interaction of the user with the information retrieval system. The focus is on interfaces which facilitate the process of specifying a query and provide a good visualization of the results.
The topic Multimedia Modeling & Searching discusses the utilization of multimedia data with information retrieval systems. The focus is on modeling, indexing, and searching multimedia data such as voice, images, and other binary data.
The part on applications of IR is composed of three interrelated topics: The Web, Bibliographic Systems, and Digital Libraries. Techniques developed for the first two applications support the deployment of the latter.
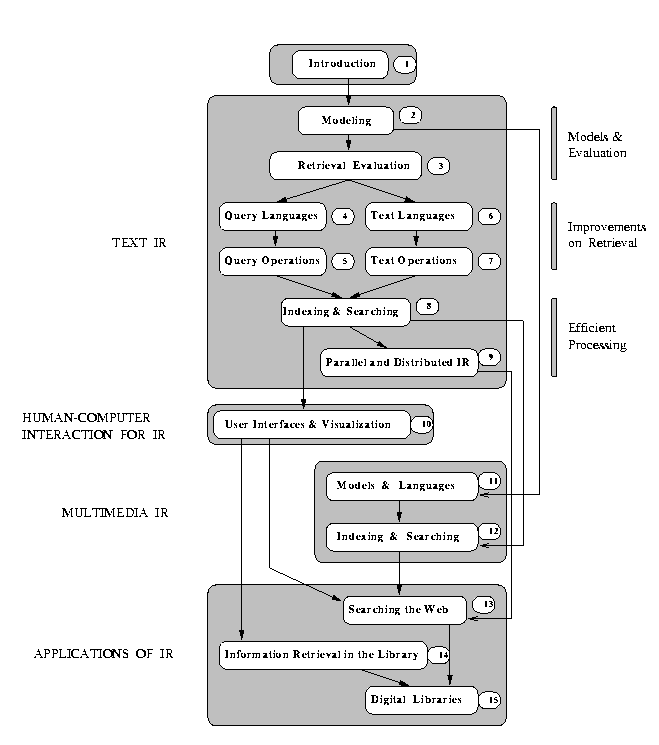
The eight topics distinguished above generate the 14 chapters, besides this introduction, which compose this book and which we now briefly introduce.
illustrates the overall structure of this
book. The reasoning which yielded the chapters
from 2 to 15 is as follows.
In the traditional keyword-based approach, the user specifies his information need by providing sets of keywords and the information system retrieves the documents which best approximate the user query. Also, the information system might attempt to rank the retrieved documents using some measure of relevance. This ranking task is critical in the process of attempting to satisfy the user information need and is the main goal of modeling in IR. Thus, information retrieval models are discussed early in Chapter 2. The discussion introduces many of the fundamental concepts in information retrieval and lays down much of the foundation for the subsequent chapters. Our coverage is detailed and broad. Classic models (Boolean, vector, and probabilistic), modern probabilistic variants (belief network models), alternative paradigms (extended Boolean, generalized vector, latent semantic indexing, neural networks, and fuzzy retrieval), structured text retrieval, and models for browsing (hypertext) are all carefully introduced and explained.
Once a new retrieval algorithm (maybe based on a new retrieval model) is conceived, it is necessary to evaluate its performance. Traditional evaluation strategies usually attempt to estimate the costs of the new algorithm in terms of time and space. With an information retrieval system, however, there is the additional issue of evaluating the relevance of the documents retrieved. For this purpose, text reference collections and evaluation procedures based on variables other than time and space are used. Chapter 12 is dedicated to the discussion of retrieval evaluation.
In traditional IR, queries are normally expressed as
a set of keywords which is quite convenient because
the approach is simple and easy to implement. However, the
simplicity of the approach prevents the formulation of more elaborate
querying tasks. For instance, queries which refer to both
the structure and the content of the text cannot be formulated. To
overcome this deficiency, more sophisticated query languages are
required.
Chapter 4
discusses various types of query languages. Since now the user might refer to the
structure of a document in his query, this structure has to
be defined. This is done by embedding the description
of a document content
and of its structure in a text language such as the Standard Generalized Markup
Language (SGML). As illustrated in Figure ,
Chapter 6 is dedicated to the discussion
of text languages.
Retrieval based on keywords might be of fairly low quality. Two possible reasons are as follows. First, the user query might be composed of too few terms which usually implies that the query context is poorly characterized. This is frequently the case, for instance, in the Web. This problem is dealt with through transformations in the query such as query expansion and user relevance feedback. Such query operations are covered in Chapter 5. Second, the set of keywords generated for a given document might fail to summarize its semantic content properly. This problem is dealt with through transformations in the text such as identification of noun groups to be used as keywords, stemming, and the use of a thesaurus. Additionally, for reasons of efficiency, text compression can be employed. Chapter 7 is dedicated to text operations.
Given the user query, the information system has to retrieve the documents which are related to that query. The potentially large size of the document collection (e.g., the Web is composed of millions of documents) implies that specialized indexing techniques must be used if efficient retrieval is to be achieved. Thus, to speed up the task of matching documents to queries, proper indexing and searching techniques are used as discussed in Chapter 8. Additionally, query processing can be further accelerated through the adoption of parallel and distributed IR techniques as discussed in Chapter 9.
As illustrated in Figure , all the key issues
regarding Text IR, from modeling to fast query processing, are covered
in this book.
Modern user interfaces implement strategies which assist the user to form a query. The main objective is to allow him to define more precisely the context associated to his information need. The importance of query contextualization is a consequence of the difficulty normally faced by users during the querying process. Consider, for instance, the problem of quickly finding useful information in the Web. Navigation in hyperspace is not a good solution due to the absence of a logical and semantically well defined structure (the Web has no underlying logical model). A popular approach for specifying a user query in the Web consists of providing a set of keywords which are searched for. Unfortunately, the number of terms provided by a common user is small (typically, fewer than four) which usually implies that the query is vague. This means that new user interface paradigms which assist the user with the query formation process are required. Further, since a vague user query usually retrieves hundreds of documents, the conventional approach of displaying these documents as items of a scrolling list is clearly inadequate. To deal with this problem, new data visualization paradigms have been proposed in recent years. The main trend is towards visualization of a large subset of the retrieved documents at once and direct manipulation of the whole subset. User interfaces for assisting the user to form his query and current approaches for visualization of large data sets are covered in Chapter 10.
Following this, we discuss the application of IR techniques to multimedia data. The key issue is how to model, index, and search structured documents which contain multimedia objects such as digitized voice, images, and other binary data. Models and query languages for office and medical information retrieval systems are covered in Chapter 11. Efficient indexing and searching of multimedia objects is covered in Chapter 12. Some readers may argue that the models and techniques for multimedia retrieval are rather different from those for classic text retrieval. However, we take into account that images and text are usually together and that with the Web, other media types (such as video and audio) can also be mixed in. Therefore, we believe that in the future, all the above will be treated in a unified and consistent manner. Our book is a first step in that direction.
The final three chapters of the book are dedicated to
applications of modern information retrieval: the Web, bibliographic
systems, and digital libraries.
As illustrated in Figure , Chapter 13
presents the Web and discusses the main problems
related to the issue of searching the Web for useful information.
Also, our discussion covers briefly the most
popular search engines in the Web presenting particularities
of their organization.
Chapter 0 covers commercial document databases and
online public access catalogs. Commercial document databases are
still the largest information retrieval systems nowadays. LEXIS-NEXIS,
for instance, has a database with 1.3 billion documents and attends to
over 120 million query requests annually.
Finally, Chapter 15 discusses modern digital
libraries. Architectural issues, models, prototypes, and standards are
all covered.The discussion also introduces the `5S' model
(streams, structures, spaces, scenarios and societies) as a framework for
providing theoretical and practical unification of digital
libraries.