Paper for ISKO99, Lyon, France, Oct 21-22, 1999. Draft of Oct 11, 1999.
Forme, Signification, et Structure des Systèmes à Sélectionner du Savoir
Form, Meaning, and Structure in Knowledge Selection Systems
Michael Buckland,
Professor,
School of Information Management and Systems,
University of California, Berkeley, CA, USA
"Une bibliographe contemporaine soucieuse de clarté a lancé cette brève définition: Un document est une preuve à l'appui d'une fait." (Suzanne Briet, 1951, 7)
Outline
1. With what are we concerned? Theories of Knowledge Organization may deal with abstract concepts. Operational systems deal only with physical, concrete objects. "Documents" as signifying objects.
2. Indexicality. Suzanne Briet.
3. What do we do with documents?
3.1. Selection: We select documents: We assemble them into collections and we retrieved individual documents from collections. Both are selection activities.
3.2. Representation: We derive surrogates of documents. We create modified versions of documents and we create descriptions and representations of them.
3.3. Use.
4. The Structure of Selection Systems. Automatic indexing: KWIC, SMART. The creation and use of a library catalog. Sets and two kinds of operations on the sets: partitioning the members and transforming the members.
5. Multiple, coexisting vocabularies are present.
6. Matching and mapping between vocabularies.
7. Definition of "vocabulary" as "range" or "repertoire" in knowledge selection system. Metadata as description; as a language activity. Metadata as language.
8. Human Language tends to indeterminate. Language is dynamic and unstable. The indeterminancy of meaning in language. Therefore the meaning of metadata is liable to be unstable. Mapping meaning between vocabularies. Dewey's Relativ Index. Berkeley DARPA project "Search Support for Unfamiliar Metadata Vocabularies.
Conclusion.
When I was invited to present a grand introduction to indexing systems in the past, in the present and in the future. That would be too much of me. I will present some ideas concerning information selection systems, specifically: With what form of phenomena are we concerned? What is the structure of the systems for selecting recorded knowledge? What is the role of meaning? My presentation summarizes work at Berkeley with my colleagues over the past decade.
1. With what are we concerned?
The members of ISKO may be concerned with the structure of knowledge. However, when we use any kind of technology to develop operational information systems we are no longer dealing directly with abstract concepts but with bits and books and other physical objects. Technology is necessarily physical. So we are concerned only indirectly with knowledge. We must concern ourselves with signs, with representations of knowledge, with physical objects considered to be significant. One could say that we are concerned with documents, but, potentially, with documents in any material form. Documents are not only of text.
Use of the word "document" is this sense is not new. The 1937 International Institute for Intellectual Cooperation, an agency of the League of Nations, developed, in collaboration with the Union Français des Organismes de Documentation, technical definitions of "document" and related technical terms in English, French and German versions, including:
Document : Toute base de connaissance, fixé matériellement, susceptible d'être utilisée pour consultation, étude ou preuve. Exemples: manuscrits, imprimés, représentations graphiques ou figurés, objets de collections, etc...
Document : Any source of information, in material form, capable of being used for reference or study or as an authority. Examples: manuscripts, printed matter, illustrations, diagrams, museum specimens, etc.... (Anon. 1937: 234)
2. Indexicality.
Suzanne Briet (1894-1989), librarian, documentalist, and historian, developed the concept of a "document" further in 1951 in her interesting manifesto, Qu'est-ce que la documentation? She begins with the statement that "Un document est une preuve à l'appui d'un fait" ("A document is evidence in support of a fact." Briet, 1951, 7). She then elaborates: A document is
"...tout indice concret ou symbolique, conservé ou enregistré, aux fins de représenter, de reconstituer ou de prouver un phénomène ou physique ou intellectuel."
("any physical or symbolic sign, preserved or recorded, intended to represent, to reconstruct, or to demonstrate a physical or conceptual phenomenon". (Briet, 1951, 7).
The implications are that documentation (today one might say Information Management) should not be viewed as being concerned with texts but with access to any kind of evidence and that the evidence (the documents) is physical. Note that Briet uses the word "indice." I believe that this implies that an object becomes evidence (a document) when and only when the object has somehow been placed the object-as-document in a relationship (positioned "indexically") with other evidence (other documents).
A more modern idea would be that meaning is constructed by the viewer. That any object might, in some situation, be considered to be significant, to be evidence, to be a document. Therefore any object can be regarded as potentially signifying. Any object is potentially a "document." Nevertheless, we retain two assumptions from Briet: that all documents are physical ("concret") and that the essence of documentation (now-a-days "Information management") is that objects are purposefully placed in indexical relationships. These indexical relationships are, of course, the special interest of the members of ISKO.
3. What do we do with documents?
In addition to being created, documents are selected, represented, and used.
3.1. Selection.
We assemble documents into collections and we retrieve documents from collections. Collection development and document retrieval are generally considered to be different activities, but there are fundamental similarities. Collection development and document retrieval are both selection activities. In both cases one or more documents is given a privileged position relative to other documents. We may speak now of information retrieval systems and search engines, but more than searching and retrieving is involved, there is also a process of choosing, of selection. I prefer the terminology of the 1930s: "Machines à sélectionner".
3.2. Representation.
We derive modified versions of documents and descriptions of them. These are or can be at least surrogates for the original documents. We make "metadata" ("metadonnées") concerning the "data" ("données."). That is to say that we create bibliographic descriptions There is a continuum from the briefest index entry to a complete version of the document with extensive bibliographic description. At base, we derive new representations of existing documents.
3.3. Use.
Individuals use documents rather unpredictably. Ordinarily we do not know who (if anyone) will use a given document (if ever). And it is generally unclear what kind of use (careful reading, quick skimming, examination of one small section only) and the intellectual or practical consequences will be. Use of metadata has the same characteristics as the use of other documents, except that metadata records are very short and so there is less basis for knowing what meaning the indexer intended.
4. Structure.
Let us look more closely at examples of the processes of selecting and representation.
4.1. Automatic indexing: KWIC. Given a text in machine-readable form we can program a machine to derive various representations of it. Each word (with its adjacent words to provide textual context) can be listed to create a KWIC index. Each line of a KWIC index is a descriptive statement -- an indexing statement -- concerning at least some part of the original document. The sum of the lines in a KWIC index pertaining to each document constitutes an mechanical representation of that document. The arrangement of the keywords is alphabetical.
More elaborate representations can be derived from the frequency of occurrence of individual words in the document, as in the vector space models (e.g. in the SMART system), create a mechanical representation of documents.
4.2. A library catalog: Consider the creation of bibliographic records for an abstracting service or the cataloging of a document for a library: The cataloger creates a bibliographic record that is a representation of the book. The record is derived partly from the document itself (e.g. title, author's name, date) and partly from other sources known to the cataloger (e.g. a national bibliography or a union catalog such as OCLC). The catalog record is a representation of the book, following techniques and conventions concerning the format and content of bibliographic descriptions (e.g. ISBD, AACRII, LCSH, LCC).
However, the work of the cataloger may become modified by the syntactical structure imposed by the editor of the catalog (e.g. authority control concerning forms of names; vocabulary control in subject headings).
Meanwhile, the user of the library has a query. The form of the user's query may not match exactly the form of entries in the catalog, so a modified version of the query needs to be derived which corresponds more closely to the vocabulary of the catalog.
The next step is the comparison of the query with the catalog. To the extent that there is a match, a selected (retrieved) set is derived. In online systems the retrieved set is usually arranged into some preferred order (e.g. author) before presentation to the user.
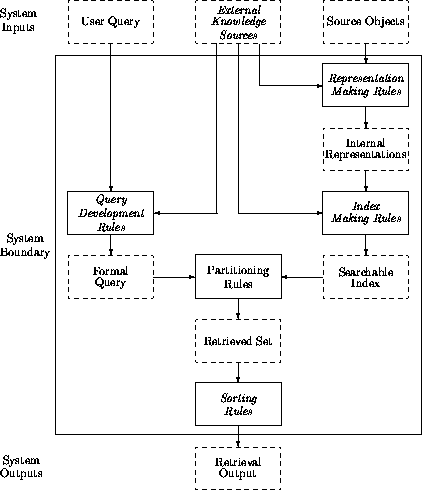
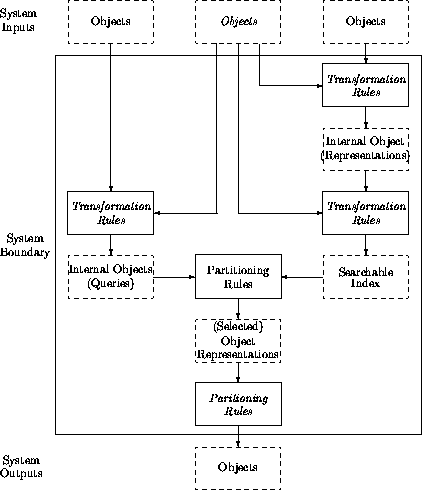
Also, note, as shown in shown as a diagram in Figure 2, that the operations that derive each new set are of one or other of only two kinds of operation:
(i) They are a rearrangement of the prior set, for example the retrieved set is a separation (partitioning) of the set of selected records from the set of records that have not been selected; or
(ii) They may be transformations of individual members of the prior set (e.g. deriving catalog records from the documents).
These two kinds of operation are the two activities that we noted above in the section "What do we do with documents?": Selection; and the creation of representations (or versions) of documents. Investigations by Dr Christian Plaunt and myself indicate that the structure of all and every kind of bibliographical system for filtering or retrieving documents can be represented as a sequence of these two simple operations on sets of documents (or sets of representations of documents. At least, we have not yet found any exceptions. (For a detailed analysis see Plaunt 199?; for a summary see Buckland & Plaunt 1994)
5. Multiple Vocabularies Co-exist.
All selection systems involve multiple vocabularies. Even in the most primitive case, where one unedited text is searched with an unedited query, there are at least two vocabularies:
1. The vocabulary (or vocabularies) of the author(s) of the documents searched; and
2. The vocabulary of the searcher.
In operational selection systems the number of vocabularies is likely to be much larger. An online library catalog, for example, would ordinarily include an additional three: The two already noted, plus:
3. The vocabulary of the cataloger, used in creating representations of the documents, modifies, replaces, and / or supplements the author's vocabulary;
4. "See," "See also," and other syndetic structure modify, replace, or supplement the cataloger's vocabulary; and
5. The vocabulary of the searcher as formulated as a search query.
In brief there are always multiple different vocabularies in use, minimally the author's and the searcher's, commonly many more different vocabularies are present simultaneously. The unrealistic hope is that these vocabularies will be identical, or even compatible, but there are no grounds for assuming that they will be.
If one extends a search one finds additional vocabularies. Here is an example: I decided to search for material on "coastal pollution." I looked in MELVYL, the University of California library catalog, which uses the Library of Congress Subject Headings, for books and in MEDLINE, which uses MeSH, for articles. In both systems the phrase "Coastal Pollution" is not used and a Boolean search for the two keywords "Coastal" and "Pollution" was unsuccessful. Material existed in both systems, however. The subject headings that had been assigned were, in ranked order:
LCSH: Marine pollution; Coastal zone management; Water -- Pollution; Petroleum industry and trade; Beach erosion; Coasts; Barrier islands; Coastal changes; etc.
MeSH: Seawater; Water pollution; Bacteria; Water microbiology; Air pollution; Environmental monitoring; Bathing beaches; Environmental pollution; etc.
Note the variety and how little the two lists have in common. The subject headings used are plausible, but who could be expected to imagine more than a few of them? It is easier to recognize pertinent terms than to predict what they will be. In this case, at least three
different vocabularies were simultaneously in play: LCSH, MeSH, and mine.
6. Matching and Mapping Between Vocabularies
Precisely because there is a multiplicity of vocabularies, there is always a possibility of mismatch in any transition between vocabularies, a dissonance in meaning. If the searcher asks for A and the author wrote B, they might be expressing the same meaning in different ways (synonyms), or they might both write A and be meaning different things (homographs).
[ADD MORE ON FORM AND MEANING FROM CoLIS3 PAPER]
Intermediate vocabularies (of the cataloger, the syndetic structure, the formulated query) could be regarded as intended to normalize term usage so that any discrepancies are rectified. The cataloger's subject heading rectifies the author's title by representing the topic of the document in a standardized vocabulary. Experienced searchers know how to modify their own or others' statement of need in terms the system will respond to usefully.
There are as many re-representations in vocabulary as there as transitions between vocabularies. Each re-representation provides an opportunity to rectify dissonances between selector and document, but it can also create dissonances. In the example of "Vietnamese Conflict" the cataloger's vocabulary is at variance with both authors' and searchers', thereby creating a dissonance and creating a problem, that requires an additional transitional vocabulary if it is to be rectified. In this case a cross-reference: VIETNAM WAR use VIETNAMESE CONFLICT would rectify the discrepancy. Alternatively, a good search intermediary (human or computerized) might know enough to prompt a change of terminology to adapt to the system's vocabulary.
7. Definition of "Vocabulary"
We have implicitly assumed that we are talking about ordinary language, French or English, but if we think that the concept of vocabulary is of any importance in information systems, as I have claimed, then maybe we should treat "vocabulary" as more than a loan word from language studies. If the concept of vocabulary is important, then we should seek an understanding of what we mean by "vocabulary" that fits systems of knowledge organization in an intellectually satisfying manner.
The Oxford English Dictionary (1989, vol 19, 721) provides four definitions of "Vocabulary."
1. A collection or list of words with brief explanations of their meanings.
2. The range of a language of a particular person, class, profession, or the like.
3. The sum or aggregate of words composing a language; and
4. Figuratively, A set of artistic or stylistic forms, techniques, movements, etc, available to a particular person, etc.
The underlying notion is that "vocabulary" denotes an enumeration of the different expressions of meaning, the repertoire of representational forms. In linguistics the words "type" and "token" are used, where every instance of a word is a "token," and each different kind of word is a "type." The "range" or "repertoire" of different types could be called the vocabulary. So using "vocabulary" for the range or repertoire of index terms or subject headings would be appropriate.
Metadata as Language
In knowledge organization the terms used to express meaning are often either rather unnatural adaptations of natural language (e.g. God -- Knowableness -- History of Doctrines -- Early Church, ca. 30-600) or use an artificial notation, such as 330 in the Dewey Decimal Classification to denote Economics. Indeed such systems for the representation of meaning are a specialty of the field. The use of such descriptive systems is a kind of language activity. It has been recognized for many years that metadata constitute a form of language. Before the word "metadata" was adopted, it was usual for specialists, such as Maurice Coyaud (1966) to refer to categorization systems as "documentary languages," "indexing language,"or "metalanguages." The explanation is that describing is a language act, that metadata such as classifications and thesauri were ways of describing documents, and that they could, therefore, be described as languages for documentation or "documentary languages." Similarly, for the same reason that "meta" was prefixed to "data" to create the term "metadata," so also documentary languages were called "metalanguages."
It would, therefore, be very appropriate in information management to extend the use of "vocabulary" to refer to the range or repertoire of allowed terms in a thesaurus, of numbers used in a classification scheme, and of codes in any categorization. In the specialized context of knowledge organization, there seems no reason not to use "vocabulary" as a technical term to denote the range or repertoire of any MARC field or other metadata field.
Treating "vocabulary" a technical term to denote the range of any metadata field opens up additional possibilities, because the entire structure of digital library systems can be represented in terms sets (or collections) and transitions from a set to a derived set. There appear to be only two kinds of transition.
9. Human Language Usage tends to be Indeterminate
Vocabulary tends to be indeterminate for two different reasons. First, the word (value) may be unfamiliar for the individual. For example, how many people know that to search for the topic "automobile" one should look for term "TL 205" in the Library of Congress Classification, for "180/280" in the U.S. Patent Classification, and for "3711" in the Standard Industrial Classification? For this reason, the creation of indexes to metadata can be very helpful. Obviously an index from the words with which a searcher approaches an information system ("entry vocabulary") to categorization codes using artificial notation is needed, e.g., the Relative Index to the Dewey Decimal Classification. However, we find that an index is also needed when "natural" language is used as metadata. For example, a search using "Automobiles" will find nothing in the U.S. import and export statistics. Data can be found using "Car" but this data refer to railway and tramway rolling stock. Data relating to automobiles are under "Passenger Motor Vehicles, Spark Ignition Engine," which is descriptive but unexpected.
A second reason for the indeterminacy of vocabulary is that the use of language is unstable: Meanings change.
Conclusions
If this analysis is correct, then there are lots of consequences. Because it is a form of language, systems for knowledge organization are always less than fully determinate.
Value-based issues of service matter.
Formal theories of information science, using, for example, logic or the "information theory" of Shannon and Weaver, are necessarily incomplete.
Much of the "digital library" research is concerned with issues of infrastructure, and not central to digital libraries.
Language, understanding, representation, meaning,... these are the central concerns.
References
Anon. (1937). La terminologie de la documentation. Coopération Intellectuelle 77, 228-240.
Buckland, M. K. 1999. The Landscape of Information Science: The American Society for Information Science at 62. Journal of the American Society of Information Science,
Buckland, M. K. 1999. Vocabulary as a Central Concept in Library and Information Science. In Digital Libraries: Interdisciplinary Concepts, Challenges, and Opportunities. Proceedings of the Third International Conference on Conceptions of Library and Information Science (CoLIS3, Dubrovnik, Croatia, 23-26 May 1999. Ed. by T. Arpanac et al. Zagreb: Lokve, pp 3-12.
Buckland, M. K. 1997. What is a "document"? Journal of the American Society for Information Science 48, no. 9: 804-809. Also Document Numérique (Paris) 2, no. 2 (1998): 221-230.
Buckland, M. and others. 1999. Mapping Entry Vocabulary to Unfamiliar Metadata Vocabularies D-Lib Magazine 5 (1) January 1999. Online at: http://www.dlib.org/dlib/january99/buckland/01buckland.html
Buckland, M. K. & C. Plaunt. 1994. On the Construction of Selection Systems. Library Hi Tech 12:4:15--28. http://www.sims.berkeley.edu/~buckland/papers/analysis/analysis.html
Coyaud, M. 1966. Introduction a l'étude des langages documentaires. Paris: Klincksieck.
Plaunt [dissertation]