Michael Buckland
School of Information Management & Systems
University of California, Berkeley, CA, USA 94720--4600
Christian Plaunt
Advanced Technology Group, Apple Computer, Inc.
One Infinite Loop, MS 301--3KM, Cupertino CA 94015
These tasks with their differing problems have, historically, been treated as separate and different. Examination and comparison of these three processes reveal similarities and differences between the three levels. The three selecting processes are fundamentally the same in theory. The differences in practice are seen as arising from differing deficiencies in internal structure or lack of metadata. Identification of these deficiencies provides a basis for an agenda of research and development.
This paper examines the process of selection at three levels: Selecting libraries to look in; selecting documents within a library; and selecting data within documents. We use the term ``selecting'' as a general term to include filtering, retrieval, routing, and searching, all variations of search where the outcome of the search is uncertain, which distinguishes ``selecting'' from ``look-up''. ``Data'' is used to here to mean parts or subsets of a document, any fragments of text, images, numbers, other symbols from which we may learn.
Libraries, documents, data: This is the way libraries are used. First select a library to visit, then select a document, then select which part or parts of it to read. Sometimes we only look at one very small part; sometimes we may read through all the parts.
The task of selecting which library to look in is not, of course, new, but it has taken on a new importance. Much research and development concerning digital libraries is, understandably, concerned with the creation of digital libraries (``repositories''). Yet this situation is, in a sense, ironic because a central, distinguishing feature of the emerging digital library environment is that digital networking reduces the dominating ``localness'' of paper-based library technology. With collections of documents on paper, it is of great importance that copies of the documents that you will need are in your local collection. But, to the extent that we move to a digital library environment, the significance of the local library collection diminishes. Improved ease of access to remote library collections makes the use of non-local (digital) libraries more feasible and more attractive. With the World Wide Web, it matters little where the web site is located. Note that we are referring to libraries' collections, not to other library services and not to librarians.
The improved access and, therefore, increased use of remote libraries makes selecting which library to use a much more important activity. It is, however, a problem that has received little systematic attention, perhaps because it is a library users' problem more than a library provider's problem.
Descriptive directories of libraries and their collections have existed for centuries, but we think that they have not been used much. There have also been some quantitative measures of the relative strengths of collections, e.g. ``Shelflist counts,'' based on counts of shelflist cards in a library for each numerous subject categories defined in terms of the Library of Congress Classification numbers and, more recently, the ``Conspectus'' approach in which, for each collection, the character as well as the size of the holdings on each topic is evaluated.
Libraries' internal systems have also changed in a manner relevant to our discussion. For years the objective was to connect the online catalog with the library's internal technical services system. Now the interest is in evolving the online catalog into a gateway to online resources everywhere, not only to books and serial titles held locally but to other collections elsewhere and, through indexing and abstracting services, to articles in periodicals. The library's online catalog is increasingly designed to provide access to resources at all three levels: to remote library collections; to documents; and to the extent that they are accessible, to parts of documents [11].
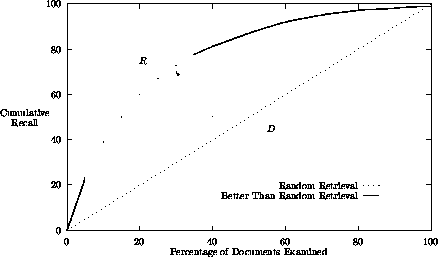
The retrieval process is commonly shown as a Recall Curve, showing the cumulative increase in the number of relevant documents found as the search is expanded to retrieve more documents. A conventional cumulative Recall graph is shown in Figure 1.
: Cumulative recall curve for document retrieval. D is
the expected result of random retrieval. R is the better-than-random
retrieval provided by an information retrieval system.
Retrieving documents randomly from a collection would yield the straight diagonal line D. Better-than-random retrieval yields a convex curve, R. With better-than-random retrieval, marginal retrieval diminishes as retrieval continues, yielding a cumulative Recall curve of the shape shown in Figure 1. The better the retrieval effectiveness (the better the selecting), the more convex the curve R becomes and the greater the separation of curve R from line D in the direction of the arrow. (For a more detailed discussion of Recall curves see [4].)
The problem of selecting libraries can be defined with three decisions:
Each decision can be seen as a comparison of the probable marginal benefit of searching in the next library compared with the probable marginal cost. The marginal benefit can be formulated in terms of the number of relevant documents not previously found, i.e. the complement of the set of relevant documents in the prospective next library to be searched relative to the union of the documents already found in the set of libraries already searched. The decision has two components: Deciding which library would have the highest benefit-cost ratio and then deciding whether undertaking the search is likely to be worthwhile. The problem can be seen as a special case of Search Theory. (For a more detailed discussion of selecting libraries see [3].)
The benefit of the search as it progresses through any given set of libraries in any given order can be expressed as the cumulative number of relevant documents found. See Figure 2.
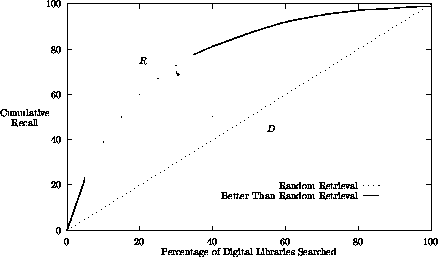
: Cumulative recall curve for retrieval across
libraries. D is the expected result of random retrieval, R is the
better-than-random retrieval provided by an information retrieval system.
The cumulative benefit curve in Figure 2, showing how the number of relevant documents increases as the number of libraries selected looks like the conventional cumulative Recall curve in Figure 1. This resemblance invites comparison of the two different tasks: Selecting libraries from a set of libraries and, the usual focus of attention, selecting documents from within a collection of documents. And, if we can compare conventional document selection with selection at a higher level of aggregation --- selecting collections (libraries) of documents --- why not also look at a lower level of aggregation: at the contents of documents. After all, it is not usually the totality of a document that is of interest, but, rather, one or more individual pieces within it. We call this selecting data and we mean the selecting of passages of text, images, numeric data, or other fragments from within a single document. (Discussions in the literature distinguishing ``data retrieval'' from ``document retrieval'' need to be treated with caution because the distinction between ``data'' and ``document'' has sometimes been confused with the difference between ``known item searches'' and ``subject searches'' [1, pp. 105,].) In this discussion the definitions should be clear: Here we are concerned with the selection (in effect the ordering) of objects at three different levels of aggregation:
We have simply defined three levels of aggregation. There are others. At a higher level of aggregation, one could select a network (set) of libraries among several networks. In the other direction, pieces of text, etc. (our ``data'') can themselves be divided in to phrases, words, characters, bits, or pixels. Further, a library's collection is often divided into a set of collections; a document is often composed of smaller documents (e.g. periodical is composed of multiple volumes); and so on. For this discussion we use the three levels noted above: Libraries (collections), documents, and data (parts of documents).
So far we have taken an empirical approach, examining selection at each level and showing that there are similarities in the structure even though there may be practical difficulties with the structure or metadata at each level. We could have reached the same conclusion from first principles. What follows is a development of ideas first discussed in Kyoto in 1992 [2] and presented in much more detail by Buckland & Plaunt [5].
Analysis of the components of selection systems reveal that even the most complex filtering and retrieval systems can be represented (modeled) in terms of three primitive elements: The notion of collections (loosely, sets) and two types of functional operations on those collections
It appears that all selecting systems at all levels can be modeled as a sequence of operations on collections using these three primitive components iteratively. In this way we find from a theoretical path an underlying similarity in selection processes at any level.
A conventional document retrieval cumulative recall curve measures, by definition, the increase in the number of distinct relevant documents retrieved as the search is expanded through the collection as shown in the cumulative curve in Figure 1. We have noted the similarity to it of the graph of the selection of libraries in Figure 2, but, in a sense, Figure 2 should not be this way. The direct analog of a conventional recall curve at the library search level would be to have the vertical scale showing a cumulative count of relevant libraries as the search extends through a set of libraries, not of documents. This could have been done, but it makes no sense to do so because the contents of libraries is (or can be) known in more detailed terms, in numbers of relevant documents.
Measuring libraries by whether each library is relevant or is not-relevant seems excessively crude and raises the question of the threshold relevance to be used. Would any, even a tiny amount, of relevance, be enough to cause a library to be deemed to be a relevant library? It is much better to avoid this crudeness and use a more refined, a more detailed measure of benefit by using a metric from the next lower level in the hierarchy, the number of relevant documents retrieved. We can measure the marginal benefit of searching a library, not by counting relevant and non-relevant libraries, but with calibration at the finer level of the units at the next lower level of analysis, documents.
If it makes sense to use a finer unit of measurement from the next lower level in our hierarchy for library selection, why not do the same in document selection? Might it not also, by the same argument, be excessively simple to judge documents as simply relevant or not relevant? Again, how ``relevant'' does it have to be --- or how much of it has to be relevant --- for the whole document to be deemed relevant? By the reasoning we applied in our discussion of libraries, it would seem better to move down a level and compare documents in terms of how much of each one is of marginal benefit.
One might say that probabilistic retrieval systems avoid the crudeness of binary relevance judgments because they generate a ranking of documents with respect to relevance, but this is not the case. What is generated are probability estimates that a document is or is not relevant, which is not the same as a measure of the relevant content of a document. Binary relevance judgments are still being used.
But comparing documents in a metric of the next lower level in our hierarchy (data) has problems. Library collections can be divided rather easily into their constituent elements, documents, but documents themselves are not so easy to subdivide with respect to relevance. There are physical divisions (pages and lines) and there are rhetorical divisions (chapters, paragraphs, and sentences). Back of book indexing usually refers to pages, but the physical divisions are largely irrelevant to the subject matter and the rhetorical divisions are only weakly and inconsistently related to intellectual content. Some exceptions can be found: Bibliographies and encyclopedias are documents composed of recognizable, discrete elements. Other documents commonly follow standardized rhetorical forms but in a much less clearly and usefully defined way.
The advantages of dividing documents into separate conceptual units, into hypertextual nodes, was recognized in the seventeenth century and received detailed attention from Hartlib and Drury and from Leibniz. This interest was renewed when there was interest in applying modern technology to information management [14]. Already by 1911 the German chemist Wilhelm Ostwald and his colleagues in an organization called Die Bruecke (The Bridge) were discussing the ``monographic principle,'' their name for the hypertextual division of documents into smaller units which could then be organized independently [6,17]. They saw such a development as similar in nature and in significance to Gutenberg's introduction of movable printing type. Commenting on the ease with which bibliographies lend themselves to being subdivided and even rearranged, Paul Otlet wrote in 1918 [13,12] of the need
``...to detach what the book amalgamates, to reduce all that is complex to its elements... This is the `monographic principle' pushed to its ultimate conclusion. ... What is a book, in fact, if not a continuous line which has initially been cut to the length of a page and then cut again to the length of a justified line? Now this cutting up, this division, is purely mechanical; it does not correspond to any division of ideas.'' [12, pp. 149,]
Otlet foresaw ``selection machines'' searching among these smaller units of recorded knowledge and workstations for manipulating and processing them [12, pp. 150,], but how to divide documents into conceptual pieces remains an unsolved problem. There is research in this direction and some of it explores how parts of documents might be used in various information retrieval tasks. Examples include automatic discovery of the topic structure of text [7], use of rhetorical boundaries (e.g. chapters, paragraphs, and sentences) to improve retrieval performance [8], and the automatic creation of hypertext links within documents [16]. However, their effective use outside the laboratory may still be some way off.
Selecting libraries would be easier if there were not duplication in libraries' collections of documents. Documents held in one library are often held in other libraries also. Without this duplication, estimates of marginal benefit, the number of relevant documents that would be retrieved from the next library searched, would relatively straightforward. But there is much duplication between existing libraries and, with duplication, the marginal benefit of the next library depends not only on the relevant documents in that library's collection, but also on how many of those documents have already been found in the libraries already selected. This means that the marginal benefit of searching a library does not depend only on that library's collection, but also on the other libraries' collections also. Analyses of individual libraries (e.g. shelflist counts and Conspectus) do not help in this, but analysis of location data in union catalogs such as OCLC can be used.
One can identify identical documents, copies of the same publisher's edition, but, beyond that, identifying duplication of contents among documents seems impractical because the duplication is not clearly enough defined to be identified. One can imagine a world in which documents are composed of a selection of data-elements, all drawn more or less duplicatively from a shared population of hypertext passages and data-elements [9,10]. Some web pages composed primarily of links to other web pages begin to assume that form, but documents are not yet designed in such a way that one could know whether and when multiple documents have the same, duplicative content. Such systematic, duplicative use of common data elements is not the norm and, we think, is unlikely to become the norm.
As a practical matter it is more difficult to predict which library one should search next than it is to decide which document within a library one should look at next. Why? Because, at least in conventional libraries there is a searchable representation of each document, a catalog record, containing descriptive metadata. This is lacking for libraries. The conclusion is that if we are to be able to search cost-effectively in the digital library universe, then we shall need some kind of catalog record and cataloging code to represent entire libraries as well as individual documents. Searching for data in a document is more difficult than searching for documents in a library collection not only because of the weak internal structure, but also because of the lack of descriptive metadata for each section of data. There is some precedent in ``analytical'' cataloging and in the use, earlier this century, of the Universal Decimal Classification for the subject categorization of parts of documents, but these are labor-intensive solutions.
Selecting libraries, selecting documents, and selecting data are consecutive stages in a single process. Improved effectiveness and improved efficiency are desirable in each of these three activities. We want to move the recall curve in the direction of the arrow in Figure 1 and in Figure 2 and in any comparable figure for data selecting, but improvement may not be equally possible or an equally good investment at all of the three levels. Because each is part of a larger process, trade-offs are possible: Investing in improved selecting of libraries may matter less than (or be less feasible or more expensive than) improved selecting of documents within collections. Improved retrieval of data from within documents might, in principle, compensate for weakness in the selecting of the documents. Depending on the nature of the search, it maybe cost-effective (or necessary) to tolerate weak performance at one level if selecting performance is good at another level. For example, if only a few documents are desired, economical but weak library selecting may not matter if document selecting is reliable within the libraries. If document selecting is weak, then that may be compensated for if the selecting of the libraries and/or the selecting of data were effective.
There is, in principle, a fundamental similarity in selecting at all three levels, selecting libraries, selecting documents, and selecting data. In practice, what is feasible varies importantly because of
These similarities and differences are summarized in Table 1.
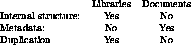
Table 1: Summary of some of the differences and similarities
between libraries and documents.
Examining the consequences of these analyses offers a large and promising agenda for international research development and practice in digital libraries.
This work was supported in part by NSF, NASA, DARPA Digital Libraries Initiative grant IRI-941334 ``The Environmental Electronic Library'' and by DARPA contract AO# F477 ``Search Support for Unfamiliar Metadata Vocabularies''.